It is out there! The build number is 3215.
http://support.microsoft.com/kb/943656/
Wednesday, December 19, 2007
Monday, December 10, 2007
EXEC AT
With every release there are really some features that you seem to miss, maybe because they are small or maybe because you just do not use that functionality that often.
That is how I recently stumbled upon a nice feature that has been added in SQL Server 2005 but I had never seen before.
EXEC AT allows you to execute queries on a linked server just like OPENQUERY and OPENROWSET but with a little less limitations. OPENQUERY and OPENROWSET for example do not accept variables for their parameters and they act like a table and thus limit you from executing certain statements like DDL.
EXEC AT on the other hand can take parameters:
EXEC sp_addlinkedserver [MyLinkedServer], 'SQL Server';
EXEC
(
'SELECT [LanguageID], [Description]
FROM myDB.dbo.Translations
WHERE TranslationID = ?;', 1000
) AT [MyLinkedServer]
It can do DDL:
EXEC
(
'USE myDB;
CREATE TABLE myTable
(myId int NOT NULL PRIMARY KEY,
myVarChar varchar(100) NULL
)'
) AT [MyLinkedServer]
It can take a username:
EXEC
(
'SELECT [LanguageID], [Description]
FROM myDB.dbo.Translations
WHERE TranslationID = ?;', 1000
) AS USER = 'WesleyB' AT [MyLinkedServer]
And last but not least it can take a variable:
DECLARE @SQLStmt nvarchar(max)
SET @SQLStmt = 'SELECT [LanguageID], [Description] FROM myDB.dbo.Translations'
EXEC(
@SQLStmt
) AT [MyLinkedServer]
It may not be the most funky feature in SQL Server 2005 but it really has potential when you are working with linked servers.
That is how I recently stumbled upon a nice feature that has been added in SQL Server 2005 but I had never seen before.
EXEC AT allows you to execute queries on a linked server just like OPENQUERY and OPENROWSET but with a little less limitations. OPENQUERY and OPENROWSET for example do not accept variables for their parameters and they act like a table and thus limit you from executing certain statements like DDL.
EXEC AT on the other hand can take parameters:
EXEC sp_addlinkedserver [MyLinkedServer], 'SQL Server';
EXEC
(
'SELECT [LanguageID], [Description]
FROM myDB.dbo.Translations
WHERE TranslationID = ?;', 1000
) AT [MyLinkedServer]
It can do DDL:
EXEC
(
'USE myDB;
CREATE TABLE myTable
(myId int NOT NULL PRIMARY KEY,
myVarChar varchar(100) NULL
)'
) AT [MyLinkedServer]
It can take a username:
EXEC
(
'SELECT [LanguageID], [Description]
FROM myDB.dbo.Translations
WHERE TranslationID = ?;', 1000
) AS USER = 'WesleyB' AT [MyLinkedServer]
And last but not least it can take a variable:
DECLARE @SQLStmt nvarchar(max)
SET @SQLStmt = 'SELECT [LanguageID], [Description] FROM myDB.dbo.Translations'
EXEC(
@SQLStmt
) AT [MyLinkedServer]
It may not be the most funky feature in SQL Server 2005 but it really has potential when you are working with linked servers.
Tuesday, December 04, 2007
SQL Server 2005 Books Online (September 2007)
Because I have a day off my colleague said I should stop working and blog something.
Since inspiration comes mostly at work I will keep this one simple.
The updated Books Online for SQL Server 2005 are available here.
Since inspiration comes mostly at work I will keep this one simple.
The updated Books Online for SQL Server 2005 are available here.
Monday, November 26, 2007
Sequential GUIDs
Today we found a table that was perfect for testing the newsequentialid() default. My colleague killspid thought it might be useful to talk about it and said "Blog it!".
This new feature has been added to SQL Server 2005 although it was available in SQL Server 2000 with the addition of an extended stored procedure written by Gert Drapers.
The Books Online state the following for the newsequentialid function:
"Creates a GUID that is greater than any GUID previously generated by this function on a specified computer." I can hardly say I ever saw a statement more simple but yet so complete.
Anyway, we decided to play around a bit with the sequential GUID too determine if this statement said it all. One of the most important limitations is that it can only be used as a default for a column with the uniqueidentifier type, doing otherwise will result in the following error:
"The newsequentialid() built-in function can only be used in a DEFAULT expression for a column of type 'uniqueidentifier' in a CREATE TABLE or ALTER TABLE statement. It cannot be combined with other operators to form a complex scalar expression.".
It's a default so can we override the contents? Well it turns out you can but there is nothing sequential about that is there?
But why would you want a GUID to be sequential? Because it makes quite a good clustering key candidate. It's unique, static, relatively narrow and sequential. All these factors make it a nice alternative to an identity for some tables. The good news is that it helped us going from a 2 seconds process to a 500 msecs process and all we had to do is change the newid() default to newsequentialid() and of course change the fillfactor since it would be a waste to keep it low with a sequential key. Should you run off and change all your defaults? No, because as always it all depends!
Here is a little test script that proves a few of these points:
SET NOCOUNT ON
GO
CREATE TABLE myGuidTest
(myGuid uniqueidentifier DEFAULT(NewSequentialID()))
GO
CREATE TABLE myGuidTest2
(myGuid uniqueidentifier DEFAULT(NewSequentialID()))
GO
--Let's see if it really is "greater than any GUID previously generated by this function on a specified computer"
INSERT INTO myGuidTest VALUES (default)
GO 5
INSERT INTO myGuidTest2 VALUES (default)
GO 5
INSERT INTO myGuidTest VALUES (default)
GO 5
SELECT * FROM myGuidTest ORDER BY 1
GO
SELECT * FROM myGuidTest2 ORDER BY 1
GO
--Can we insert our own GUID?
DECLARE @newID uniqueidentifier
SET @newID = NewID()
SELECT @newID
INSERT INTO myGuidTest VALUES (@newID)
GO
INSERT INTO myGuidTest VALUES (default)
GO 5
SELECT * FROM myGuidTest ORDER BY 1
--Cleanup
DROP TABLE myGuidTest
DROP TABLE myGuidTest2
This new feature has been added to SQL Server 2005 although it was available in SQL Server 2000 with the addition of an extended stored procedure written by Gert Drapers.
The Books Online state the following for the newsequentialid function:
"Creates a GUID that is greater than any GUID previously generated by this function on a specified computer." I can hardly say I ever saw a statement more simple but yet so complete.
Anyway, we decided to play around a bit with the sequential GUID too determine if this statement said it all. One of the most important limitations is that it can only be used as a default for a column with the uniqueidentifier type, doing otherwise will result in the following error:
"The newsequentialid() built-in function can only be used in a DEFAULT expression for a column of type 'uniqueidentifier' in a CREATE TABLE or ALTER TABLE statement. It cannot be combined with other operators to form a complex scalar expression.".
It's a default so can we override the contents? Well it turns out you can but there is nothing sequential about that is there?
But why would you want a GUID to be sequential? Because it makes quite a good clustering key candidate. It's unique, static, relatively narrow and sequential. All these factors make it a nice alternative to an identity for some tables. The good news is that it helped us going from a 2 seconds process to a 500 msecs process and all we had to do is change the newid() default to newsequentialid() and of course change the fillfactor since it would be a waste to keep it low with a sequential key. Should you run off and change all your defaults? No, because as always it all depends!
Here is a little test script that proves a few of these points:
SET NOCOUNT ON
GO
CREATE TABLE myGuidTest
(myGuid uniqueidentifier DEFAULT(NewSequentialID()))
GO
CREATE TABLE myGuidTest2
(myGuid uniqueidentifier DEFAULT(NewSequentialID()))
GO
--Let's see if it really is "greater than any GUID previously generated by this function on a specified computer"
INSERT INTO myGuidTest VALUES (default)
GO 5
INSERT INTO myGuidTest2 VALUES (default)
GO 5
INSERT INTO myGuidTest VALUES (default)
GO 5
SELECT * FROM myGuidTest ORDER BY 1
GO
SELECT * FROM myGuidTest2 ORDER BY 1
GO
--Can we insert our own GUID?
DECLARE @newID uniqueidentifier
SET @newID = NewID()
SELECT @newID
INSERT INTO myGuidTest VALUES (@newID)
GO
INSERT INTO myGuidTest VALUES (default)
GO 5
SELECT * FROM myGuidTest ORDER BY 1
--Cleanup
DROP TABLE myGuidTest
DROP TABLE myGuidTest2
Tuesday, November 20, 2007
Some new features in SQL Server 2008 - November CTP
First of all I am very glad that 2 of my requests seem to have made it to SQL Server 2008:
Of course there is a lot more in this CTP 5 and the first thing you will notice is the new installer which is a lot better than in previous versions. A great addition is the ability to configure the location of tempdb at install time.

But let us look at the nifty stuff that has been added to SQL Server:
- Cumulative waitstats info https://connect.microsoft.com/SQLServer/feedback/ViewFeedback.aspx?FeedbackID=275212
- A central registered server list https://connect.microsoft.com/SQLServer/feedback/ViewFeedback.aspx?FeedbackID=136596
Of course there is a lot more in this CTP 5 and the first thing you will notice is the new installer which is a lot better than in previous versions. A great addition is the ability to configure the location of tempdb at install time.
But let us look at the nifty stuff that has been added to SQL Server:
- Backup compression
- Intellisense
- Filestream support
- Many improvements on partitioning
- Plan freezing
- Resource Governor
- Change tracking
- Transparent Data Encryption
- Spatial data support
- Lock escalation can be defined on table level
- ...
Obviously there are many other new features available, as well in the Database Engine as in the other services like Reporting Services, Analysis Server and Integration Services. I suggest that you download the new Books Online to read about all the exciting new features because this time there are too many to discuss them in one post.
A quick note, when installing on Windows Server 2008 RC0 I had to start setup.exe because the autorun splash screen did not work and returned several javascript errors.
Monday, November 19, 2007
SQL Server 2008 November CTP (CTP5)
Fire up those virtual servers because the latest CTP is out!
Get it here:
http://www.microsoft.com/downloads/details.aspx?FamilyId=3BF4C5CA-B905-4EBC-8901-1D4C1D1DA884&displaylang=en
What's new:
https://connect.microsoft.com/SQLServer/content/content.aspx?ContentID=5470
Get it here:
http://www.microsoft.com/downloads/details.aspx?FamilyId=3BF4C5CA-B905-4EBC-8901-1D4C1D1DA884&displaylang=en
What's new:
https://connect.microsoft.com/SQLServer/content/content.aspx?ContentID=5470
Tuesday, November 13, 2007
Update statistics before or after my index rebuild?
I already posted some information about this some time ago and now I finally have some confirmation from a real guru about this often asked question.
So to wrap it up, a reindex updates the statistics with a full scan because he has to read through the entire index anyway. It does however not update non-index statistics so therefore you might want to trigger an update anyway. The nice thing about SQL Server 2005 is that he will only update the statistics if it is necessary if you use sp_updatestats.
A little test script to demonstrate some of these points.
Q4) In a maintenance plan, is it a good idea to do an index rebuild followed by an update statistics?
A4) No! An index rebuild will do the equivalent of an update stats with a full scan. A manual update stats will use whichever sampling rate was set for that particular set of statistics. So - not only does doing an update stats after an index rebuild waste resources, you may actually end of with a worse set of stats if the manualy update stats only does a sampled scan
So to wrap it up, a reindex updates the statistics with a full scan because he has to read through the entire index anyway. It does however not update non-index statistics so therefore you might want to trigger an update anyway. The nice thing about SQL Server 2005 is that he will only update the statistics if it is necessary if you use sp_updatestats.
A little test script to demonstrate some of these points.
Saturday, November 10, 2007
TechEd Barcelona 2007 - The Return
Yesterday was sadly the last day of our visit to Barcelona. What is there to say? I saw many interesting sessions and has a nice chat with Bob Beauchemin and Michael Rys who were both at the Belgian party. And not to forget, I also had a nice evening with the Microsoft Belgium folks.
A couple of interesting things I remembered and will probably be blogging about once the SQL Server 2008 CTP5 bits are available.
A couple of interesting things I remembered and will probably be blogging about once the SQL Server 2008 CTP5 bits are available.
- CTP 5 should be released by the end of this month (more information should be available this Monday).
- Filtered indexes are cool and allow you to mimic an Oracle behavior as a side effect. You can now create a unique index but allow more than one NULL.
- Sparse columns and column sets are really cool (especially for data warehousing).
- Change tracking, which is used for sync services, can also be used for other purposes by yourself (and maybe one day for Merge Replication?).
- Filestream will be a valuable addition but should be carefully considered. One of the biggest drawbacks in my opinion is the lack of database mirroring support.
- There are actually names for a lot of things we have implemented.
- Data mining can be used for purposes you might not think of at first as was displayed by Rafal Lukawiecki.
- Many people still do not understand that a database engine is not a psychic, if you have no way of logically telling it which records you need it will not use the book of Nostradamus to guess. Oracle and Delphi were actually psychics by the way.
- Belgian fries still rule and yet they are called French fries. If you want to find out why check out Wikipedia.
I hope to get back to you soon because that would mean CTP5 was released ;-)
Tuesday, November 06, 2007
TechEd Barcelona 2007
Greetings from Barcelona.
We have seen some fine sessions already on SQL Server and VSDBPro.
I will post some more information after the event to wrap up the interesting stuff we have seen.
We have seen some fine sessions already on SQL Server and VSDBPro.
I will post some more information after the event to wrap up the interesting stuff we have seen.
Tuesday, October 30, 2007
SQL Server 2005 SP2 Cumulative Hotfix Package 5 - Announced
We are in the process of gradually upgrading our servers to CU4 now (build 3200) and here is the next announcement.
I know many people think they are messing about with SQL Server 2005 and that it has more bugs than other products but this is not the case.
Releasing this many hotfixes is all part of a new strategy of the "incremental servicing model" which is explained here.
So do not panic, updates like this will be released every 2 months.
I know many people think they are messing about with SQL Server 2005 and that it has more bugs than other products but this is not the case.
Releasing this many hotfixes is all part of a new strategy of the "incremental servicing model" which is explained here.
So do not panic, updates like this will be released every 2 months.
Saturday, October 27, 2007
PowerShell
Many UNIX people will probably say "boring" when they see PowerShell. UNIX has always supported great flexibility in scripting, of course they did not have a great GUI like Windows does. But as server management is getting more and more complex because of the large environments and many flavors of server software it was time to start thinking without the GUI because it does tend to work a bit slower as compared to a script enabled server and some things are just impossible using only a GUI. With scripts you can check for certain conditions and take actions automatically and appropriately based on these conditions.
The answer to this is PowerShell, a command line shell and scripting environment which will enable you to manage almost everything. One of its most powerful features is the ability to extend it with .NET components as well as being able to use the out of the box .NET Framework objects.
For Exchange 2007 they have first written the PowerShell layer and based the GUI entirely on these scripts. The GUI will also support a Script This Action (sound like we were ahead in SQL Server) which will create the PowerShell script for you.
At the customer we have something we call DCS (Data Conversion Scripts), basically it means going from one version of the database to the next version. We had a great .NET console application combined with some batch files which does this for us. Although this worked great we felt this was getting too complex to manage because we do parallel development and support different version at the same time. A new system was required using a simpler concept which my colleague killspid had proven was possible.
We started out with a batch file which used sql scripts with SQLCMD to perform the DCS task. Although this worked fine the lead DBA had a new requirement which needed more logic and was hard to do in a batch file or T-SQL. We decided to rewrite the DCS in PowerShell and I am very glad we did. Using a PowerShell script, SQLCMD and an XML config file we now support all the requirements and we have much more control than we did in the previous versions. The support for variables in SQLCMD has also proven itself very useful so do not underestimate the power of SQLCMD either.
I must admit the syntax and way of working is a bit peculiar at first because you have to lose the .NET mindset and get into the scripting mindset. If you are used to creating administrative scripts you will probably have less of a problem.
Tip: if you want to get rid of the output SQLCMD gives you in PowerShell add >$null behind it.
eg. sqlcmd -SmyServer -dmyDatabase -E -b > $null
The answer to this is PowerShell, a command line shell and scripting environment which will enable you to manage almost everything. One of its most powerful features is the ability to extend it with .NET components as well as being able to use the out of the box .NET Framework objects.
For Exchange 2007 they have first written the PowerShell layer and based the GUI entirely on these scripts. The GUI will also support a Script This Action (sound like we were ahead in SQL Server) which will create the PowerShell script for you.
At the customer we have something we call DCS (Data Conversion Scripts), basically it means going from one version of the database to the next version. We had a great .NET console application combined with some batch files which does this for us. Although this worked great we felt this was getting too complex to manage because we do parallel development and support different version at the same time. A new system was required using a simpler concept which my colleague killspid had proven was possible.
We started out with a batch file which used sql scripts with SQLCMD to perform the DCS task. Although this worked fine the lead DBA had a new requirement which needed more logic and was hard to do in a batch file or T-SQL. We decided to rewrite the DCS in PowerShell and I am very glad we did. Using a PowerShell script, SQLCMD and an XML config file we now support all the requirements and we have much more control than we did in the previous versions. The support for variables in SQLCMD has also proven itself very useful so do not underestimate the power of SQLCMD either.
I must admit the syntax and way of working is a bit peculiar at first because you have to lose the .NET mindset and get into the scripting mindset. If you are used to creating administrative scripts you will probably have less of a problem.
Tip: if you want to get rid of the output SQLCMD gives you in PowerShell add >$null behind it.
eg. sqlcmd -SmyServer -dmyDatabase -E -b > $null
Tuesday, October 23, 2007
Table Valued Parameters
Before SQL Server 2008 the most common way to pass data from one procedure to another would be by creating a temporary table, fill it with the required data and then call another procedure that uses that temporary table. Although this is not a disaster it does have some flaws like not being strongly typed. The weak typing of temp tables in this scenario make it a perfect spot for issues. There are other solutions using XML but these tend to be more complex than necessary for the 'simple' thing you are trying to do... pass structured data around.
SQL Server 2008 now supports something called Table Valued Parameters (or TVP) which can help you in these situations. TVP's make it possible to use a "table" as a parameter for a procedure. A couple of limitations apply, TVP's can only be READONLY in the procedure that define them as a parameter and they can only be used as an input parameter. Apart from this the same rules apply to TVP's as to table variables for example no DDL can be executed against a TVP and no statistics are kept for TVP's.
A little example will make it very clear.
SQL Server 2008 now supports something called Table Valued Parameters (or TVP) which can help you in these situations. TVP's make it possible to use a "table" as a parameter for a procedure. A couple of limitations apply, TVP's can only be READONLY in the procedure that define them as a parameter and they can only be used as an input parameter. Apart from this the same rules apply to TVP's as to table variables for example no DDL can be executed against a TVP and no statistics are kept for TVP's.
A little example will make it very clear.
--Create test table
CREATE TABLE myUsers
(ID int, UserName varchar(50), UserRole tinyint);
GO
--Create the required type
CREATE TYPE UserRoleType AS TABLE
( UserRole tinyint );
GO
--Create procedure that takes the type as a parameter (READONLY is required)
CREATE PROCEDURE GetUsersInRole
@UserRoleType UserRoleType READONLY
AS
SELECT UserName
FROM myUsers u
INNER JOIN @UserRoleType ut ON u.UserRole = ut.UserRole
GO
--Insert some test data (multiple inserts in one go, another new feature)
INSERT INTO myUsers
VALUES (1, 'Wesley', 1),
(2, 'Tom', 2),
(3, 'Patrick', 2),
(4, 'Jan', 3),
(5, 'Bregt', 3)
--Throw in a new dmv to look at the type and check dependencies if you like
--SELECT * FROM sys.table_types
--SELECT * FROM sys.dm_sql_referenced_entities ('dbo.GetUsersInRole', 'OBJECT')
GO
--Lookup action
DECLARE @UserRoleType
AS UserRoleType;
--Lets use another new features (initialize var on declare!)
DECLARE @Admin tinyint = 1
DECLARE @PowerUser tinyint = 2
DECLARE @User tinyint = 3
--Add parameter values to the table valued parameter
--INSERT INTO @UserRoleType VALUES (1), (2)
INSERT INTO @UserRoleType VALUES (@Admin), (@PowerUser)
--Call stored procedure with specific type (remember the post is about table valued parameters)
EXEC GetUsersInRole @UserRoleType;
GO
--Clean up
DROP PROCEDURE GetUsersInRole
DROP TYPE UserRoleType
DROP TABLE myUsers
Tuesday, October 16, 2007
SQL Server 2005 SP2 Cumulative Hotfix Package 4 - Released
It is out there! We are at the nice round build 3200.
Same as with CU3 there is also no download available.
http://support.microsoft.com/default.aspx/kb/941450
Same as with CU3 there is also no download available.
http://support.microsoft.com/default.aspx/kb/941450
Tuesday, October 02, 2007
Some I/O improvements in Windows Server 2008
Windows Server 2008 offers a lot of new features that are very visible like Internet Information Server 7.0, a whole new virtualization model, Server Manager and many many more. But being a SQL Server person I am interested in other things that have been improved. These not so visible features are mostly I/O related since databases are a synonym for I/O. Also note that many (if not all) of these changes also apply to Windows Vista.
I/O Completion Port improvement
Before Windows Server 2008 a thread that issued an async I/O also executed the I/O completion task causing a context switch which is expensive. The I/O completion is now deferred until the thread pulls the I/O off the completion port preventing this context switch.
I/O prioritization
This is completely new to the OS, not only do your processes have a priority but also the I/O's that are triggered by these processes have their priority. This priority is based on the thread priority but can be set on the I/O itself too.
I/O Performance improvements
Using the GetQueuedCompletionStatusEx API call enables Windows to retrieve multiple completion port entries in one call.
Prior to Windows Server 2008 the Memory Manager and I/O system limited every I/O request internally to 64KB, larger requests were divided into multiple 64KB parts. This limit has been removed so every request can now be issued as a whole, meaning less transitions to kernel-mode to send the I/O to your storage device.
NUMA improvements
When working with SQL Server 2005 and later you will most likely encounter more and more NUMA enabled machines. In Windows Server 2008 more memory allocations procedures have been updated to be NUMA aware and I/O interrupts direct their completion to the node that initiated the I/O. An addition to the NUMA APIs also allows applications to specify the preferred node.
SMB2
According to the people who designed SMB2 this should help performance of large file copies over the network with factor 30 to 40. This will not really help your SQL Server performance but it will certainly get your backups to other servers faster.
For more information about kernel changes in Windows Server 2008 check out this great webcast by Mark Russinovich.
I/O Completion Port improvement
Before Windows Server 2008 a thread that issued an async I/O also executed the I/O completion task causing a context switch which is expensive. The I/O completion is now deferred until the thread pulls the I/O off the completion port preventing this context switch.
I/O prioritization
This is completely new to the OS, not only do your processes have a priority but also the I/O's that are triggered by these processes have their priority. This priority is based on the thread priority but can be set on the I/O itself too.
I/O Performance improvements
Using the GetQueuedCompletionStatusEx API call enables Windows to retrieve multiple completion port entries in one call.
Prior to Windows Server 2008 the Memory Manager and I/O system limited every I/O request internally to 64KB, larger requests were divided into multiple 64KB parts. This limit has been removed so every request can now be issued as a whole, meaning less transitions to kernel-mode to send the I/O to your storage device.
NUMA improvements
When working with SQL Server 2005 and later you will most likely encounter more and more NUMA enabled machines. In Windows Server 2008 more memory allocations procedures have been updated to be NUMA aware and I/O interrupts direct their completion to the node that initiated the I/O. An addition to the NUMA APIs also allows applications to specify the preferred node.
SMB2
According to the people who designed SMB2 this should help performance of large file copies over the network with factor 30 to 40. This will not really help your SQL Server performance but it will certainly get your backups to other servers faster.
For more information about kernel changes in Windows Server 2008 check out this great webcast by Mark Russinovich.
Sunday, September 30, 2007
Majority Quorum Model
Windows Clustering Services have been around for some time and most if not all critical servers in large enterprise are probably running on this technology. An important part of a cluster is the quorom disk which holds vital information to keep your cluster up and running. The two options in Windows 2003 for this quorum are shared disk quorum model where all nodes share the same quorum and the majority node set model where each node has a replicated copy of the quorum. The shared disk model is used most often because a lot of the clusters consist of two nodes. Do note that there is an update for Windows Server 2003 that enables a "File Share Witness" to create a majority node set cluster with just 2 nodes (KB921181 - steps required).
In Windows Server 2008 they have merged these two models which is now called Majority Quorum Model. Before Windows Server 2008 the quorum disk was a single point of failure. The risk was obviously low because quorum drives are usually installed on redundant storage devices but even highly redundant storage may fail sometime. In Windows Server 2008 however the quorum disk or as it is now called witness disk is no longer a single point of failure. Clustering now uses a 'vote' system where each node and the quorum device can be assigned a vote. A cluster remains online if just a single vote is lost meaning your cluster will continue to work even when the quorum is lost.
More information about failover clustering in Windows Server 2008 can be found here:
http://www.microsoft.com/windowsserver2008/failover-clusters.mspx
Saturday, September 29, 2007
Windows Server 2008 RC0
You probably are all aware of this but since I am on a holiday I have a good excuse to be a bit later.
Microsoft has released Windows Server 2008 Release Candidate 0. This is great news since there are a lot of exciting features in Windows Server 2008 for you to play with. They have also included the long awaited Hypervisor platform for your virtualization needs.
Get this free download here.
Thursday, September 13, 2007
SQL Server 2005: Migration aftermath
I guess we can safely say that the migration was a success. It was quite a flat migration since we needed to guarantee a "backout" to SQL Server 2000, the only changes that were done is the replacement of SCSIPort with StorPort drivers (this was the only server left to migrate) and we decided to change the physical implementation of the database.
A couple of preliminary results since replication is still running and it obviously has impact on performance:
Long running transactions:
Before: 70.000/day > 100 msec - 1.000/day > 1000 msec
After: 14.000/day > 100 msec - 650/day > 1000 msec
Long running CUD transactions:
Before: 40.000/day > 100 msec - 250/day > 1000 msec
After: 4.000/day > 100 msec - 100/day > 1000 msec
Avg Disk Secs/Read:
Before: 12 msec
After: 9 msec
Avg Disk Secs/Write:
Before: 15 msec
After: 9 msec
Job duration dropped with over 50%.
Now it is time to start implementing new features like partitioning, service broker, vardecimal and hopefully many more. We have a lot of ideas floating around in our heads but unfortunately there are a couple of other priorities to take care of first Since we were no longer happy with our existing reindexing job we did decide to rewrite it from scratch and this gave us the opportunity to implement online reindexing.
I would like to thank all of my colleagues and the people from Microsoft who made this migration possible. I also apologize to all the colleagues I had to send away from my desk during the migration preparation ;-)
A couple of preliminary results since replication is still running and it obviously has impact on performance:
Long running transactions:
Before: 70.000/day > 100 msec - 1.000/day > 1000 msec
After: 14.000/day > 100 msec - 650/day > 1000 msec
Long running CUD transactions:
Before: 40.000/day > 100 msec - 250/day > 1000 msec
After: 4.000/day > 100 msec - 100/day > 1000 msec
Avg Disk Secs/Read:
Before: 12 msec
After: 9 msec
Avg Disk Secs/Write:
Before: 15 msec
After: 9 msec
Job duration dropped with over 50%.
Now it is time to start implementing new features like partitioning, service broker, vardecimal and hopefully many more. We have a lot of ideas floating around in our heads but unfortunately there are a couple of other priorities to take care of first Since we were no longer happy with our existing reindexing job we did decide to rewrite it from scratch and this gave us the opportunity to implement online reindexing.
I would like to thank all of my colleagues and the people from Microsoft who made this migration possible. I also apologize to all the colleagues I had to send away from my desk during the migration preparation ;-)
Friday, September 07, 2007
SQL Server 2005: Migration imminent and something about TF4618
So we are back at the point of no return. This Sunday we will be migrating our largest SQL Server 2000 to SQL Server 2005. During the first week we will use transactional replication to ensure a 'backout' in case of failure. Last year when we attempted to migrate this server we unfortunately hit the TokenAndPermUserStore issue and had to rollback the migration.
As explained in this post we created some tests script which were able to degrade the performance significantly. There were a couple of hotfixes for issues concerning the TokenAndPermUserStore cache with the latest being build 3179. We eventually did our tests on build 3186 which is the version we will be going to production with, unfortunately we were still able to degrade the performance with our scripts.
We looked at a couple of alternatives to prevent this decrease from happening and as far as we know there are 3 ways to prevent the TokenAndPermUserStore cache from growing too large and these are:
As explained in this post we created some tests script which were able to degrade the performance significantly. There were a couple of hotfixes for issues concerning the TokenAndPermUserStore cache with the latest being build 3179. We eventually did our tests on build 3186 which is the version we will be going to production with, unfortunately we were still able to degrade the performance with our scripts.
We looked at a couple of alternatives to prevent this decrease from happening and as far as we know there are 3 ways to prevent the TokenAndPermUserStore cache from growing too large and these are:
- add the user(s) that access the database to the sysadmin role
- create a scheduled job that issues DBCC FREESYSTEMCACHE ('TokenAndPermUserStore')
- use TF4618
After we ran our tests with trace flag 4618 we found that the TokenAndPermUserStore cache remained very small (less than 1MB) and our response times were very stable. The catch with this trace flag is that it has to be enabled by adding -T4618 to the SQL Server startup parameters (using DBCC TRACEON does not help in this case). What this trace flag does is evict old entries when new entries get inserted to keep the cache small. Because this extra work might cause an increase in CPU usage be sure to carefully monitor this. We did not see any significant increase in our stress tests.
We also decided to take 1 more "risk" and that is a reorganization of our database file layout. A legacy layout because of the previous SAN was 4 files for data and 4 files for the non-clustered indexes. Since we noticed a great difference in response times of the luns between the 2 filegroups we now use 1 filegroup spread over the 8 luns, this resulted in a great balance over all luns and improved response times.
After many hours of reorganizing, stress testing, replication testing and going mad we are finally there. We had days of paranoia and days of euphoria and we ended with euphoria, hopefully it will remain this way. Monday will tell us if everything was as well as we suspected so I suppose the only thing that remains is to wish us luck :-)
Monday, August 20, 2007
SQL Server 2005 SP2 Cumulative Hotfix Package 4
Probably a bit early since the previous package is not yet available, but knowledge is power they say.
http://support.microsoft.com/kb/941450
http://support.microsoft.com/kb/941450
Wednesday, August 08, 2007
SQL Server 2005 SP2 Cumulative Hotfix Package 3
Keep an eye out for KB939537 which will be the next cumulative hotfix package for SQL Server 2005 SP2. Unfortunately the fix itself is not yet available for download.
Any guesses on the build number? I'm going for 3193 :-)
*EDIT*
It is build 3186 so I was pretty close but too pessimistic ;-)
Any guesses on the build number? I'm going for 3193 :-)
*EDIT*
It is build 3186 so I was pretty close but too pessimistic ;-)
Wednesday, August 01, 2007
Some new features in SQL Server 2008 - July CTP
Date and time
As many of you already know we finally have a separate date and time datatype in SQL Server 2008. This is not the only new option for date and time however, there a couple of other new datatypes like datetime2 and datetimeoffset.
- Date
The data datatype takes 3 bytes and has a range from 0001-01-01 through 9999-12-31 - Time
The time datatype takes 3 to 5 bytes depending on the fractional second precision. Time has a range from 00:00:00.0000000 through 23:59:59.9999999. The default precision is 7 meaning hh:mm:ss.nnnnnnn and depending on the precision you specify - with time(x) where x is a number from 0 to 7 - the storage size differs . From 0 to 2 time will take 3 bytes, from 3 to 4 it will take 4 bytes and up to 7 it will take 5 bytes. - Datetime2
Although this makes me shiver as it makes me think of varchar2 it is a great datatype. Datetime2 takes from 6 to 8 bytes and has a range of 0001-01-01 through 9999-12-31. It also implements the same fractional second precision option as the time datatype. From 0 to 2 datetime2 will take 6 bytes, from 3 to 4 it will take 7 bytes and up to 7 it will take 8 bytes. - Datetimeoffset
The datetimeoffset datatype takes from 8 to 10 bytes and has the same properties as datetime2 but the difference with the other datatypes is that datetimeoffset is timezone aware. The fractional second precision again defines the storage size, from 0 to 2 datetimeoffset will take 8 bytes, from 3 to 4 it will take 9 bytes and up to 7 it will take 10 bytes. There are also a couple of datetimeoffset related functions like SWITCHOFFSET and TODATETIMEOFFSET.
HierarchyID
Another new datatype is the hierarchyid datatype which represents the position in a tree hierarchy. I did not have the time to play with it yet but from what I have read it implements 2 special indexing methods, depth-first and breadth-first. It also has a couple of related function like GetAncestor, GetDescendant, IsDescendant, ...
Object Dependencies
The new management views sys.sql_expression_dependencies,
Page corruption
The new management view sys.dm_db_mirroring_auto_page_repair contains information about automatic repair attempts on mirrored databases (page restores from the mirror database).SQL Server Extended Events
Built in support for the ETW (Event Tracing for Windows) engine to help you trace, log and debug problems. For more information about using ETW with SQL Server check out this post.
I recommend you to play with SQL Server 2008 yourself since there is already a very long list of new things to learn in this CTP! There are still a couple of other features in the July CTP which I have not seen yet so I hope I will find some time to experiment with these too.
TokenAndPermUserStore continued
Dirk G. from MCS Belgium informed me about another hotfix for the TokenAndPermUserStore issue. Build 3179 contains another fix for this cache (the latest build is 3182 by the way). The official description is "The TokenAndPermUserStore cache store may continue to grow steadily and decrease performance".
Check out the hotfixes here. Unfortunately they are on-demand so you will have to contact Microsoft to obtain this build.
Tuesday, July 31, 2007
SQL Server 2008 - July CTP
It's play time :-)
A lot of people will be very happy... date and time is available as a seperate datatype!
Wednesday, July 25, 2007
MemToLeave Issue in SQL Server 2000 x86
This week we were getting "WARNING: Failed to reserve contiguous memory of Size= 131072." errors on a couple of our SQL Server 2000 machines. Since we had a lot of available memory we quickly suspected the cause to be VAS fragmentation but we needed to find the root cause and confirmation that is was indeed VAS fragmentation. This is a bit harder since SQL Server 2000 has a lot less options to investigate this as opposed to SQL Server 2005.
VAS (Virtual Address Space) is the 4 GB region (in 32-bit) where 2 GB is reserved for the kernel mode and the other 2 GB for user mode (unless you specify /3GB). Every memory allocation (including AWE mapping) for an application happens in the user mode portion of the VAS.
By default SQL Server reserves 256MB in the MemToLeave region and an additional part that is calculated as worker threads * stack size (0.5MB for SQL Server 2000 x86). This memory is reserved in the VAS and used for special memory allocations like extended stored procedures, sp_OA procedures, CLR integration and some specific memory managers. One of the properties of MemToLeave memory is that it is static and it can only be increased at startup by using the -g switch. If you wish to do this do it with great caution as VAS is only 2 GB or 3 GB on a 32 bit system. As a side note, allocations from this region are done by the Multi Page Allocator in SQL Server 2005, meaning it is not stolen from the buffer pool and consequently is not included in the Max Server Memory setting.
We contacted PSS to help us find the root cause and they instructed us to start SQL Server with -T3654 which allows you to run a command that returns information about the memory allocations SQL Server has done: DBCC MEMOBJLIST. We would have resolved the whole issue by restarting SQL Server and limit our chances to find the root cause. Since it was not a production server we decided to wait a little with the restart and continue looking for the root cause. It was a good decision since on of my colleagues noticed that there were a lot of trace files created at the same time. We have a central mechanism that uses server side traces to profile all our servers and something had gone seriously wrong this weekend. When we issued a select * from ::fn_trace_getinfo(0) on the server it showed us that there were 270 traces running. Probably because of a little bug the tool started an incredible amount of traces on the server.
When we issued a DBCC MEMORYSTATUS we got the following results:
Dynamic Memory Manager Buffers
Stolen 3728
OS Reserved 37528
OS Committed 37506
OS In Use 37502
General 1513
QueryPlan 2420
Optimizer 0
Utilities 36900
Connection 220
According to KB271624 'Utilities' is used by various utilities routines like BCP, Log Manager, parallel queries, ::fn_trace_gettable and others. Others also means buffers used for tracing. Starting the 200+ traces caused our VAS to get heavily fragmented and thus leaving us with a lot of different errors like "There is not enough storage to complete this operation", "Failed to reserve contiguous memory", login failures, etc. As you can see the 'Utilities' memory manager has 36900 buffers which is a massive amount considering the limited MemToLeave size.
So remember, even if you have lots of available memory you can still run out of memory!
VAS (Virtual Address Space) is the 4 GB region (in 32-bit) where 2 GB is reserved for the kernel mode and the other 2 GB for user mode (unless you specify /3GB). Every memory allocation (including AWE mapping) for an application happens in the user mode portion of the VAS.
By default SQL Server reserves 256MB in the MemToLeave region and an additional part that is calculated as worker threads * stack size (0.5MB for SQL Server 2000 x86). This memory is reserved in the VAS and used for special memory allocations like extended stored procedures, sp_OA procedures, CLR integration and some specific memory managers. One of the properties of MemToLeave memory is that it is static and it can only be increased at startup by using the -g switch. If you wish to do this do it with great caution as VAS is only 2 GB or 3 GB on a 32 bit system. As a side note, allocations from this region are done by the Multi Page Allocator in SQL Server 2005, meaning it is not stolen from the buffer pool and consequently is not included in the Max Server Memory setting.
We contacted PSS to help us find the root cause and they instructed us to start SQL Server with -T3654 which allows you to run a command that returns information about the memory allocations SQL Server has done: DBCC MEMOBJLIST. We would have resolved the whole issue by restarting SQL Server and limit our chances to find the root cause. Since it was not a production server we decided to wait a little with the restart and continue looking for the root cause. It was a good decision since on of my colleagues noticed that there were a lot of trace files created at the same time. We have a central mechanism that uses server side traces to profile all our servers and something had gone seriously wrong this weekend. When we issued a select * from ::fn_trace_getinfo(0) on the server it showed us that there were 270 traces running. Probably because of a little bug the tool started an incredible amount of traces on the server.
When we issued a DBCC MEMORYSTATUS we got the following results:
Dynamic Memory Manager Buffers
Stolen 3728
OS Reserved 37528
OS Committed 37506
OS In Use 37502
General 1513
QueryPlan 2420
Optimizer 0
Utilities 36900
Connection 220
According to KB271624 'Utilities' is used by various utilities routines like BCP, Log Manager, parallel queries, ::fn_trace_gettable and others. Others also means buffers used for tracing. Starting the 200+ traces caused our VAS to get heavily fragmented and thus leaving us with a lot of different errors like "There is not enough storage to complete this operation", "Failed to reserve contiguous memory", login failures, etc. As you can see the 'Utilities' memory manager has 36900 buffers which is a massive amount considering the limited MemToLeave size.
So remember, even if you have lots of available memory you can still run out of memory!
Tuesday, July 24, 2007
Visual Studio Team Edition for Database Professionals Service Release 1
Monday, July 23, 2007
Run batch multiple times
Kalen posted an awesome tip that is so simple and yet so cool I just had to refer to it.
Thursday, July 19, 2007
Even more USERSTORE_TOKENPERM
Reading this and this post reminded me of our very bad experience with the USERSTORE_TOKENPERM cache.
When we ran into our USERSTORE_TOKENPERM issue last year there was no real awareness of the problem yet (SQL Server 2005 x64 - Enterprise Edition Build 2153). It was so bad we had to revert to SQL Server 2000 because things got so slow that SQL Server started to become unresponsive. After we got everything back to the original server with SQL Server 2000 we had a couple of weeks of detective work in front of us. Having an issue with this much impact needs to be investigated and the root cause must be found before you can even think about migrating again. We had done all the steps needed before migrating like stress testing, functional jobs, system jobs, ... and yet we did not see the behavior it was showing in production.
We have spent quite some time on the phone with an Escalation Engineer from Microsoft trying to pinpoint the root cause of our problem. After we convinced the engineer that the root cause was not parallelism as he suggested we finally got some vital information that helped us understand what was happening. When he told us about the USERSTORE_TOKENPERM cache and its behavior we started running some tests and now knew what we were looking for. Sure enough the size of this cache just kept growing and the remove count certainly did not.
select
distinct cc.cache_address,
cc.name,
cc.type,
ch.clock_hand,
cc.single_pages_kb + cc.multi_pages_kb as total_kb, cc.single_pages_in_use_kb + cc.multi_pages_in_use_kb as total_in_use_kb,
cc.entries_count, cc.entries_in_use_count, ch.removed_all_rounds_count, ch.removed_last_round_count, rounds_count
from sys.dm_os_memory_cache_counters cc join sys.dm_os_memory_cache_clock_hands ch on (cc.cache_address =
ch.cache_address)
where cc.type = 'USERSTORE_TOKENPERM'
order by total_kb desc
Since it was announced that this problem would be fixed in Service Pack 2 we decided to create some test scripts that really put stress on this cache. We tried to come as close as possible to our production situation at that time which was sp_executesql for the CUD operations (UpdateBatch). Putting pressure on this cache was quite easy, have different query text so they get cached as different query plans and execute them twice since the first time it just gets inserted in the cache and the problem comes with the lookup action. We forced this behavior by executing queries with varchar parameters that increase in length every iteration. Also remember to use a login that is not a sysadmin since this causes SQL Server to skip the TokenAndPermUserStore check. We ended up creating a couple of scripts to do just this and also to monitor the cache size. The 'engine' behind it are simple command files and SQLCMD. Unfortunately I can not post the scripts since they are the property of the customer.
As far as we have seen from our tests the behavior has certainly improved in SP2. It takes a lot longer for the duration of the queries to increase and it does not increase to the point where SQL Server becomes unresponsive nor does the duration become unacceptably high. Since we are really pushing the cache to the limit it does still cause some increase in duration but not nearly to the point where SP1 gets it. We do notice however that under the constant 'hammering' of these queries even SP2 has the greatest trouble to keep the cache under control even when we call DBCC FREESYSTEMCACHE('TokenAndPermUserStore'). Obviously this scenario is not realistic since we really are trying to make it go wrong. Not only did the TokenAndPermUserStore behavior change in SP2 they cut down the size of the plan cache dramatically in SP2 too.
The conclusion however is that under Service Pack 2 we do not experience the same catastrophic behavior as before.
A lot of time has passed and we are going to migrate to SQL Server 2005 on the 9th of September. We are using a whole new .NET Framework on the application tier with a whole new data access layer, so a lot of the factors that existed that last time have now changed. We are starting our stress tests next month, if I get the chance and if we find anything peculiar I will let you know.
Hopefully this time there will not be any surprises :-(
Tuesday, July 17, 2007
The target of 'replace' must be at most one node
One of the new features of SQL Server 2005 is the integration of XML in the database. Although XML in the database is not my favorite architecture there are situations where it is useful. Since we have not really used XML in a real life project before we are slowly learning its limitations.
A limitation we recently discovered is modifying more than 1 node at a time using XML DML. This limitation is documented in the Books Online under the "replace value of" topic: "If multiple nodes are selected, an error is raised."
The only idea we could come up with is to loop through the nodes until all the nodes have been updated. Lucky for us SQL Server also supports mixing XML with special functions like sql:variable() and sql:column().
Check out the code here since blogger is giving me issues with the XML string :-(
Monday, July 16, 2007
Windows Home Server - RTM
There was not such a great buzz about this edition (at least not here in Belgium) but nevertheless it is an interesting product. It contains some nice features like a home network health monitor which makes sure all updates are applied on your home PC's, full system restores, automatic backup and many more.
Check out the announcement here and more information here
Check out the announcement here and more information here
Thursday, July 12, 2007
SQL Server 2008 Launch
SQL Server 2008, together with Visual Studio 2008 and Windows Server 2008, will be launched on the 27th of February. More information can be found here.
Greg Low once launched a nice suggestion for deferred constraints but unfortunately it did not make it to SQL Server 2008. But not to worry there are lot of other exciting features ;-)
Also some nice features in Windows 2008, for the I/O lovers: there is an internal limit of 64k per I/O request in earlier version of Windows, this limit has been removed in the new Windows core.
For Visual Studio 2008 we will see the integration of WF, WCF and WPF and of course LINQ.
Seeing the end of February date reminded me of a really stupid joke someone sent me.
So for the geeks among us:
It is March 1st and the first day of DBMS school
The teacher starts off with a role call.. Teacher: Oracle?
"Present sir"
Teacher: DB2?
"Present sir"
Teacher: SQL Server?
"Present sir"
Teacher: MySQL?
[Silence]
Teacher: MySQL?
[Silence]
Teacher: Where the hell is MySQL
[In rushes MySQL, unshaved, hair a mess]
Teacher: Where have you been MySQL
"Sorry sir I thought it was February 31st"
Wednesday, July 04, 2007
SQL Server 2005 Best Practices Analyzer (July 2007)
Although the summer (which we have not seen much of in Belgium the last 2 weeks) has started, Microsoft is still on a roll. Check out the new SQL Server 2005 Best Practices Analyzer here.
By the way, for those of you who have not bought SQL Server 2005 Practical Troubleshooting: The Database Engine, it is really a must read for every SQL Server DBA. Apart from troubleshooting information it also contains a lot of 'inside' information about how SQL Server 2005 works, I just love that stuff but maybe that's just me :-)
*EDIT*
A nice blog post here.
Monday, July 02, 2007
SQL DMVStats
Tom Davidson and Sanjay Mishra bring us a great set of reports and scripts to generate a Dynamic Management View Performance Data Warehouse.
Check out this great solution here.
This is actually something we had on our to do list for quite some time so this will save us a lot of development work.
Check out this great solution here.
This is actually something we had on our to do list for quite some time so this will save us a lot of development work.
Monday, June 25, 2007
Synonym
Perhaps a little known feature of SQL Server 2005 but it might come in handy when you are slowly changing your database to use schema's. Synonyms allow you to define an alias for your objects and this is very helpful when you are migrating to schema's.
By using synonyms you can change your object names while retaining your 'interface' to the application and this allows for a smoother and more phased migration.
A little example with a table but remember that this also works for stored procedures, functions, etc. and it is also possible to create synonyms for remote objects (linked server).
--Create a schema
CREATE SCHEMA SchemasRock
GO
--Create a table in the default schema
CREATE TABLE dbo.myTable
(ID int)
GO
--Insert a row
INSERT INTO dbo.myTable VALUES (1)
--Move the table to the new schema
ALTER SCHEMA SchemasRock TRANSFER dbo.myTable
--Insert another row (will fail!)
INSERT INTO dbo.myTable VALUES (2)
/*
Msg 208, Level 16, State 1, Line 1
Invalid object name 'dbo.myTable'.
*/
--Create a synonym to support 'old' table name
CREATE SYNONYM dbo.myTable FOR SchemasRock.myTable
--Insert another row
INSERT INTO dbo.myTable VALUES (2)
--Select the rows
SELECT * FROM dbo.myTable
SELECT * FROM SchemasRock.myTable
--Clean
DROP SYNONYM [dbo].[myTable]
DROP TABLE [SchemasRock].[myTable]
DROP SCHEMA [SchemasRock]
By using synonyms you can change your object names while retaining your 'interface' to the application and this allows for a smoother and more phased migration.
A little example with a table but remember that this also works for stored procedures, functions, etc. and it is also possible to create synonyms for remote objects (linked server).
--Create a schema
CREATE SCHEMA SchemasRock
GO
--Create a table in the default schema
CREATE TABLE dbo.myTable
(ID int)
GO
--Insert a row
INSERT INTO dbo.myTable VALUES (1)
--Move the table to the new schema
ALTER SCHEMA SchemasRock TRANSFER dbo.myTable
--Insert another row (will fail!)
INSERT INTO dbo.myTable VALUES (2)
/*
Msg 208, Level 16, State 1, Line 1
Invalid object name 'dbo.myTable'.
*/
--Create a synonym to support 'old' table name
CREATE SYNONYM dbo.myTable FOR SchemasRock.myTable
--Insert another row
INSERT INTO dbo.myTable VALUES (2)
--Select the rows
SELECT * FROM dbo.myTable
SELECT * FROM SchemasRock.myTable
--Clean
DROP SYNONYM [dbo].[myTable]
DROP TABLE [SchemasRock].[myTable]
DROP SCHEMA [SchemasRock]
Wednesday, June 20, 2007
SQL Server 2005 SP2 Cumulative Hotfix 3175
Monday, June 11, 2007
SQL Server 2005 Books Online (May 2007)
Back to the current release of SQL Server ;-)
Get the updated Books Online here.
Get the updated Books Online here.
Wednesday, June 06, 2007
Fun with the new MERGE statement
I found some time to play with CTP3 and checked out the MERGE statement. What you achieve with it may not be rocket science and was perfectly possible with a couple of IF statements but using MERGE gives you much cleaner code. It looks like Microsoft is investing a lot in 'cleaner' coding in SQL Server 2008, which I can only welcome with great enthusiasm.
A simple example will show you exactly what the MERGE statement does.
A simple example will show you exactly what the MERGE statement does.
CREATE TABLE StagedData
(ID int, UserName varchar(20))
GO
CREATE TABLE RealData
(ID int, UserName varchar(20))
GO
INSERT INTO StagedData VALUES (1, 'Slava') , (2, 'Paul') , (3, 'Wesley')
GO
MERGE RealData r
USING
(SELECT ID, UserName FROM StagedData) staging
ON (r.ID = staging.ID)
WHEN MATCHED THEN UPDATE SET r.UserName = staging.UserName
WHEN TARGET NOT MATCHED THEN INSERT VALUES (ID, UserName)
WHEN SOURCE NOT MATCHED THEN DELETE;
GO
SELECT * FROM RealData
GO
UPDATE StagedData SET UserName = 'Kimberley' WHERE ID = 3
GO
MERGE RealData r
USING
(SELECT ID, UserName FROM StagedData) staging
ON (r.ID = staging.ID)
WHEN MATCHED THEN UPDATE SET r.UserName = staging.UserName
WHEN TARGET NOT MATCHED THEN INSERT VALUES (ID, UserName)
WHEN SOURCE NOT MATCHED THEN DELETE;
GO
SELECT * FROM RealData
GO
DELETE FROM StagedData WHERE ID = 3
GO
MERGE RealData r
USING
(SELECT ID, UserName FROM StagedData) staging
ON (r.ID = staging.ID)
WHEN MATCHED THEN UPDATE SET r.UserName = staging.UserName
WHEN TARGET NOT MATCHED THEN INSERT VALUES (ID, UserName)
WHEN SOURCE NOT MATCHED THEN DELETE;
GO
SELECT * FROM RealData
GO
DROP TABLE StagedData
GO
DROP TABLE RealData
GO
Tuesday, June 05, 2007
SQL Server 2008 - A first look
I took some time to look at the ''nifty" features in SQL Server 2008. There is a long list of new features shown in this webcast, but I doesn't look like all of them are already implemented in CTP3.
Here are some of the new features that are in this build and are quite nifty:
A great list of new features can be found here.
Here are some of the new features that are in this build and are quite nifty:
- MERGE, a very powerful statement to combine insert/updates and even deletes in a single statement
- Multiple values INSERT (eg. INSERT INTO myTable VALUES (1, 'SQL Server 2008 Rocks'), (2, 'It really does') - the example in the BOL seems to be incorrect)
- FORCESEEK query hint
- Table-valued parameters enables you to pass table variables to stored procedures or functions
- ALTER DATABASE SET COMPATIBILITY_LEVEL isof sp_dbcmptlevel
- Policy based management, this is an awesome feature that allows you to set policies on many configuration options and even naming conventions for your objects in a very flexible way (Declarative Management Framework)
- Change Data Capture, a built-in auditing mechanism
- Some new dynamic management views (sys.dm_os_memory_brokers, sys.dm_os_memory_nodes, sys.dm_os_nodes, sys.dm_os_process_memory and sys.dm_os_sys_memory)
There are probably many cool features and I'll keep you informed when I stumble upon them.
*EDIT*A great list of new features can be found here.
Monday, June 04, 2007
Is it a bird, is it an airplane? No it's the first CTP of SQL Server Katmai... I mean SQL Server 2008!
Check it out here, the first public CTP of SQL Server 2008.
Go go go :-)
Friday, June 01, 2007
SQL Server Katmai Part II
Francois Ajenstat announced in a podcast interview - at the very first Microsoft Business Intelligence Conference - that the first CTP will probably be released in the coming month!
Get your Virtual Servers ready ;-)
By the way, you can find webcasts of this conference on the resources page.
Friday, May 25, 2007
3GB PAE AWE
Tuesday, May 22, 2007
Database Snapshot vs Procedure Cache
I recently stumbled upon a KB article (KB917828) that points out some situations in which your procedure cache is cleared.
Since one of our architectures for reporting involved database snapshots I was suprised to read that your whole procedure cache is cleared when you drop a database snapshot. This may not be as dramatic as it sounds but you should closely watch the impact on your environment when the cache is cleared.
Other situations are:
Since one of our architectures for reporting involved database snapshots I was suprised to read that your whole procedure cache is cleared when you drop a database snapshot. This may not be as dramatic as it sounds but you should closely watch the impact on your environment when the cache is cleared.
Other situations are:
- A database has the AUTO_CLOSE database option set to ON. When no user connection references or uses the database, the background task tries to close and shut down the database automatically.
- A database has the AUTO_CLOSE database option set to ON. Maintenance operations are performed, such as the DBCC CHECKDB operation or a backup operation. When the operations finish, the background task tries to close and shut down the database automatically.
- You run several queries against a database that has default options. Then, the database is dropped.
- You change the database state to OFFLINE or ONLINE.
- You successfully rebuild the transaction log for a database.
- You restore a database backup.
Wednesday, May 09, 2007
SQL Server Katmai
Sunday, May 06, 2007
Visual Studio 2005 Team Edition for Database Professionals - SR1 (CTP)
For those of you who are lucky and are already working with VSDBPRO, there is a service release CTP available for download (KB936202). Make sure you read the release notes before you install.
Gert Drapers also posted some additional information on his blog.
One of the biggest enhancements, in my opinion, is the support for SQLCMD variables. This enables great flexibility in your deployment scripts.
Wednesday, May 02, 2007
Cumulative waitstats per session/query
We were troubleshooting a long running batch job when we suddenly realized that there is no easy way to get cumulative wait information for a specific session or query. With the rich information already available to us in SQL Server 2005 this might be a great addition to the product.
I decided to launch a suggestion on Microsoft Connect. This great initiative makes it possible for everyone to give suggestions to improve Microsoft's products.
Check out my suggestion here (and while you are there do vote ;-))Tuesday, April 17, 2007
A couple of interesting KB articles
Today we were installing SQL Server 2005 on our new Windows 2003 Server (SP2) cluster when we ran into the following issue: "The file C:\Windows\Microsoft.NET\Framework\Meaningless_string\mscorlib.tlb could not be loaded", the solution to this can be found in KB918685.
Dirk G from MCS Belgium was nice enough to point us to another hotfix concerning the USERSTORE_TOKENPERM issue, KB933564 contains more information about this.
KB935897 has some information about the new "Incremental Servicing Model" for SQL Server.
Dirk G from MCS Belgium was nice enough to point us to another hotfix concerning the USERSTORE_TOKENPERM issue, KB933564 contains more information about this.
KB935897 has some information about the new "Incremental Servicing Model" for SQL Server.
Monday, April 16, 2007
So what's up with all the SP2 post fixes?
Friday, April 06, 2007
WinDbg and SQL Server minidumps
Today a couple of our test servers started to act very weird. Some jobs were going incredibly slow and eventually most of them crashed causing a mini dump to be generated. The error log pointed to I/O problems with latch timeouts but there were no details on which file exactly it crashed.
The SAN and NAS management is done by another team and we had to pinpoint the problem to convince them that it was really an I/O issue. So how exactly do you do this on a server with several databases and processes?
Off to my favorite developer Bregt, I knew he had good knowledge of WinDbg so he could help us pinpoint the issue. Lucky for me Bregt is a nice guy and he explained to me how I could find the cause of the crash.
Download WinDbg which is part of the debugging toolkit provided by Microsoft.
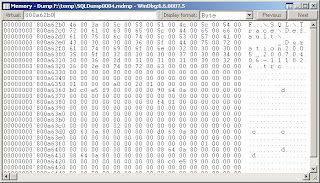
The SAN and NAS management is done by another team and we had to pinpoint the problem to convince them that it was really an I/O issue. So how exactly do you do this on a server with several databases and processes?
Off to my favorite developer Bregt, I knew he had good knowledge of WinDbg so he could help us pinpoint the issue. Lucky for me Bregt is a nice guy and he explained to me how I could find the cause of the crash.
Download WinDbg which is part of the debugging toolkit provided by Microsoft.
Start WinDbg (Run As Administrator in Vista) and configure the symbols as follows (CTRL-S)
 The url can be found in the WinDbg help and the local symbols path is one you choose (and create yourself). Don't forget to save your workspace when it asks you to (thanks again Bregt).
The url can be found in the WinDbg help and the local symbols path is one you choose (and create yourself). Don't forget to save your workspace when it asks you to (thanks again Bregt).
After you have done this you can open a crash dump (CTRL-D), this might take a while depending on the size of the dump.
Type ~kv in the command line, this gives you the call stack with the memory addresses.
Using ALT-5 you get a memory viewer, here you can check the content of the memory for the last call. It is possible however that nothing is returned for the memory address since not everything is dumped with a minidump. In our case this was "ntdll!ZwCreateFile+0xa" and this directed us to the exact filename and it was a server side trace that was being saved to a NAS drive.
How cool is that?
I feel like digging a little deeper in WinDbg when I find some time. A colleague of us (Hans De Smaele) has written a great document on this topic.
Wednesday, April 04, 2007
SQL Server 2005 SP2 - Another hotfix
This time we are at build 3159 with KB934459.
Those darn maintenance plans sure are causing mayhem lately :-)
Those darn maintenance plans sure are causing mayhem lately :-)
Tuesday, April 03, 2007
Detach/Attach migration
In our effort to consolidate some environments I had to migrate a reporting database from SQL Server 2000 to SQL Server 2005. One of the easiest ways of migrating is a simple detach and attach (sp_attach_db is deprecating and being replaced by CREATE DATABASE FOR ATTACH in SQL Server 2005).
After the attach some options have to be changed like the compatibility level, page verify checksum, etc. and as a last step I issued an sp_updatestats.
When I started the test run I noticed that it was taking very long so I started issuing some sp_who and sp_lock statements. The output showed that the same locks were being held for an unreasonable amount of time until the point that tempdb ran out of space. I had 8GB of tempdb space and the query only had to return 3 rows from a couple of tables that had less than 100 rows. I decided to run the query again and monitored tempdb usage with the new DMV sys.dm_db_file_space_usage, I immediately saw tempdb allocations rise at an incredible rate.
I decided to drop all the existing statistics and issued the same query again, this time it immediately returned the 3 rows without any trouble and without any unusual tempdb usage.
Very odd behavior but this shows the importance of statistics and the apparently subtle differences between SQL Server 2000 and SQL Server 2005. Dropping the statistics is easy in development/test but for production environments you might want to script the existing statistics and recreate them. For some unknown reason the update statistics was not as effective as expected after an attach from a SQL Server 2000 database.
*UPDATE*
Things like this are always a bit more complicated than they seem at first. After the import of the new set of data for today the query went back to the bad behavior. A strange effect was that the query worked well if I took a date range of a couple of months but failed with an interval of 1 day. The key here was of course the fact that because of a bad estimation the query plan was completely different in the two cases. Creating one index on a single field out of the ten tables that were involved in the query resulted in a different query plan being chosen and completely solved the problem.
Yet again a couple of important things are proven:
After the attach some options have to be changed like the compatibility level, page verify checksum, etc. and as a last step I issued an sp_updatestats.
When I started the test run I noticed that it was taking very long so I started issuing some sp_who and sp_lock statements. The output showed that the same locks were being held for an unreasonable amount of time until the point that tempdb ran out of space. I had 8GB of tempdb space and the query only had to return 3 rows from a couple of tables that had less than 100 rows. I decided to run the query again and monitored tempdb usage with the new DMV sys.dm_db_file_space_usage, I immediately saw tempdb allocations rise at an incredible rate.
I decided to drop all the existing statistics and issued the same query again, this time it immediately returned the 3 rows without any trouble and without any unusual tempdb usage.
Very odd behavior but this shows the importance of statistics and the apparently subtle differences between SQL Server 2000 and SQL Server 2005. Dropping the statistics is easy in development/test but for production environments you might want to script the existing statistics and recreate them. For some unknown reason the update statistics was not as effective as expected after an attach from a SQL Server 2000 database.
*UPDATE*
Things like this are always a bit more complicated than they seem at first. After the import of the new set of data for today the query went back to the bad behavior. A strange effect was that the query worked well if I took a date range of a couple of months but failed with an interval of 1 day. The key here was of course the fact that because of a bad estimation the query plan was completely different in the two cases. Creating one index on a single field out of the ten tables that were involved in the query resulted in a different query plan being chosen and completely solved the problem.
Yet again a couple of important things are proven:
- The differences in the query optimization engine between SQL Server 2000 and SQL Server 2005 make it important to test every query
- Statistics are of great importance to the query optimizer so watch them carefully and make sure they are kept up-to-date
- Having proper indexes is an absolute necessity for every environment
- Any change, how small it may seem, could have great impact on your environment
Monday, March 26, 2007
Views and the smart Query Optimizer
In general I don't really like to use views. Although they have their advantages I often see it turn out bad in projects. The main reason is that people start to use complex views that were not written for their specific functionality and many tables get touched that have nothing to do with the result they are trying to retrieve.
The query optimizer is quite intelligent when it comes to resolve the query plan for a view. It is smart enough to ignore the tables you do not need to resolve your query.
CREATE VIEW SmartView AS
SELECT i.ItemTitle, i.ItemLink, u.UserName
FROM tbl_item i
JOIN tbl_user u ON i.OwnerID = u.UserID
GO
SELECT ItemTitle, UserName FROM SmartView

SELECT ItemTitle FROM SmartView

Wednesday, March 14, 2007
Tuesday, March 13, 2007
I/O counters in Task Manager
One of my freaky habits is to check the I/O counters in the task manager. Whenever I'm doing I/O intensive stuff I like to quickly look at the MBs processed.
Whether these counters are updated or not is controlled by a registry setting (see below). You can set the value to 0 to disable it or 1 to enable it. Disabling it gives a little performance boost since Windows doesn't have to take care of the counters but on test systems I like to enable it. SQLIOSim also requires it to be enabled to get some of it's results.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\I/O System\CountOperations
By the way, Windows Server 2003 Service Pack 2 (fixlist) is getting very close. Keep an eye out for it because it contains fixes to improve performance of SQL Server 2005 under heavy load. More details will follow.
Whether these counters are updated or not is controlled by a registry setting (see below). You can set the value to 0 to disable it or 1 to enable it. Disabling it gives a little performance boost since Windows doesn't have to take care of the counters but on test systems I like to enable it. SQLIOSim also requires it to be enabled to get some of it's results.
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\I/O System\CountOperations
By the way, Windows Server 2003 Service Pack 2 (fixlist) is getting very close. Keep an eye out for it because it contains fixes to improve performance of SQL Server 2005 under heavy load. More details will follow.
Thursday, March 08, 2007
SQL Server 2005 SP2 - Cumulative Hotfix (build 9.0.3152)
A new cumulative hotfix package has been release for SQL Server 2005 SP2.
The new build number is 3152, they are really going fast these days :-)
Wednesday, March 07, 2007
SQL Server 2005 Performance Dashboard Reports
Keith Elmore, an escalation engineer at Microsoft, has created a "Performance Dashboard" for SQL Server 2005 SP2 to detect common performance issues. It uses the new Custom Reports functionality in SP2.
More info can be found here.
The files are installed in \Program Files\Microsoft SQL Server\90\Tools\PerformanceDashboard. You have to run setup.sql on the server(s) you wish to monitor (do remember Service Pack 2 is required!).
More info can be found here.
The files are installed in \Program Files\Microsoft SQL Server\90\Tools\PerformanceDashboard. You have to run setup.sql on the server(s) you wish to monitor (do remember Service Pack 2 is required!).
Tuesday, March 06, 2007
SQL Server 2005 Post SP2 Hotfix
The kind people of SSWUG warned us today about a potential problem with Service Pack 2.
And I quote:
"Important SQL Server 2005 SP2 Hotfix
If you're using SP2, you need to be sure to pick up the hotfix, to be posted today (Mar 6 2007). There is an issue with SP2 and a "mixed" environment of SQL Server versions. This issue specifically occurs in fairly small and particular circumstances. First, you have to have installed SP2. SP2 was released just a week and half ago or so, so many have this in a test environment at this point. Second, if you have an environment where pre-SP2 client utilities are in-use, if you use these utilities to open/edit cleanup processes on the SP2 servers, you can encounter the issue. SQL Server will incorrectly read the intervals set up for the cleanup processes, resulting in cleanup processes not running when expected.
We first had a report of this here on SSWUG last week. The report, and a few follow-on reports since, indicated that, after installation of SP2, packages apeared to have different intervals when they were reviewed after SP2 installation and compared with intervals set up prior to that time.
I spoke with Francois Ajenstat, Director of Product Management for SQL Server late in the day on Monday (Mar 5) and he indicated that a hotfix would be available on the SQL Server site late Mar 5/Early Mar 6 and that the SP2 bits have been (or will be at the same time) updated to include the updated code that corrects the issue.
What you need to know: Not correcting this issue could lead to data loss in some circumstances. According to Arjenstat, if you've installed SP2, you must apply the hotfix, available on the site. You should do this immediately to avoid the issues outlined here. Second, if you've downloaded and not yet installed SP2 on all or some of your servers, for those that hav not yet been installed, you need to get the newer SP2 update and be sure you're using that as you update your servers. While there are mitigating circumstances around this (versions, mixed environment, cleanup tasks), Arjenstat said they're being very open and aggressive in getting the news of the udpate out there and the updated bits available on the site immediately. If you are experiencing issues, PSS will work with you to help resolve them."
*EDIT*
The KB article can be found here. The SP2 download has also been refreshed so if you download the new SP2 install file this fix will be included.
Tuesday, February 27, 2007
Bob Beauchemin coming to the DevDays
Great news for the SQL Server people visiting the DevDays in Belgium, Bob Beauchemin will be giving a number of sessions on the second day. I will certainly be attending all of them Bob ;-)
Yet another difference in Vista Home Premium
I was trying to expose 2 drives as 1 which is possible by using dynamic disks. I'm a big fan of diskpart so I tried converting the disk using this command line utility:
diskpart
select disk 1
convert dynamic
Error: Dynamic disks are not supported by your edition
This is not a new limitation, it was actually the same for Windows XP Home Edition.
Thursday, February 22, 2007
Tuesday, February 20, 2007
Monday, February 19, 2007
Friday, February 09, 2007
The not so visible differences between Vista Editions
I was trying to run Virtual Server 2005 R2 on my Vista machine and installed IIS as mentioned below. There was one option I couldn't find however and that was "Windows Authentication".
Apparently there are more differences between the Vista editions as there are mentioned on the website.
Windows Authentication is not available on the Home Editions :-( I also noticed that the good old user manager is not available either (only the wizard interface).
More info about IIS features here
Apparently there are more differences between the Vista editions as there are mentioned on the website.
Windows Authentication is not available on the Home Editions :-( I also noticed that the good old user manager is not available either (only the wizard interface).
More info about IIS features here
Windows Vista
If you are a freak like me and can't wait to install Vista, although you know there will be many compatibility problems so early after a release, you might encounter some problems when you try to install SQL Server 2005 Express Edition on a Vista machine (MSDE will NOT be supported).
There is a website however that can help you with configuring everything to make SQL Server work on your Vista PC. So if you can't wait for Service Pack 2 check out this website.
There is also a little post-SP1 download for Visual Studio 2005 available.
And for the people who want to run Virtual Server 2005 R2 there is this link.
There is a website however that can help you with configuring everything to make SQL Server work on your Vista PC. So if you can't wait for Service Pack 2 check out this website.
There is also a little post-SP1 download for Visual Studio 2005 available.
And for the people who want to run Virtual Server 2005 R2 there is this link.
Saturday, January 27, 2007
Oops I got tagged
I got tagged by Bart Bultinck, so here it goes... 5 things you may or may not know about me
- My nickname dis4ea comes from a documentary about coffee, disphoria is extreme unhappiness and people who are addicted to coffee might suffer from it when they lack coffee.
- One of my grandmothers was actually Dutch and my father lived in The Netherlands during the first years of his life.
- My brother is a system engineer, my father worked as a manager in the technical department of a computer hardware retailer and my mother worked as a sales representative in a computer hardware retailer.
- I don't drink alcohol either (respect Bart) and it is indeed very difficult to convince people that you really don't...
- My favorite instrument is the guitar and I love all kinds of music where the guitar is the important instrument (especially blues). My favorite artists are Stevie Ray Vaughan, Joe Satriani, Buddy Guy, Jimi Hendrix and Metallica.
My turn to tag:
Subscribe to:
Posts (Atom)
