2007 here we come!
It will be the year of SQL Server 2005 SP2, Windows 2003 Server SP2, yet another SQL Server 2005 migration, the year they start building my house, elections in Belgium, the last year in my twenties, our 10th anniversary, ...
Let's hope it will not be a year of disasters and violence but that's probably too much to ask :-(
Hope to see you all again next year!
Sunday, December 31, 2006
Thursday, December 21, 2006
Wednesday, December 20, 2006
Trace Flag 1200
When you enable trace flag 1200 SQL Server gives you extensive information about all the locks being taken by a specific query or procedure.
There is a little behavior change between SQL Server 2000 and SQL Server 2005 however. In SQL Server 2000 it was a session wide flag so DBCC TRACEON (1200) was enough to get you going while SQL Server 2005 considers it a server wide flag meaning you have to use DBCC TRACEON (1200, -1) to get it going again.
Thanks to Dirk G from MCS Belgium for clearing out the difference in behavior between SQL Server 2000 and SQL Server 2005.
For SQL Server 2000 you do the following:
DBCC TRACEON (3604)
DBCC TRACEON (1200)
For SQL Server 2005 you do the following:
DBCC TRACEON (3604)
DBCC TRACEON (1200, -1)
There is a little behavior change between SQL Server 2000 and SQL Server 2005 however. In SQL Server 2000 it was a session wide flag so DBCC TRACEON (1200) was enough to get you going while SQL Server 2005 considers it a server wide flag meaning you have to use DBCC TRACEON (1200, -1) to get it going again.
Thanks to Dirk G from MCS Belgium for clearing out the difference in behavior between SQL Server 2000 and SQL Server 2005.
For SQL Server 2000 you do the following:
DBCC TRACEON (3604)
DBCC TRACEON (1200)
For SQL Server 2005 you do the following:
DBCC TRACEON (3604)
DBCC TRACEON (1200, -1)
Monday, December 11, 2006
A query cannot update a text column and a clustering key
A colleague recently got the following error message when executing an update query:
The message is clear but should actually read:
It is mentioned in the Books Online in the notes of the UPDATE statement. There is a little change in behavior between SQL Server 2000 and SQL Server 2005 however.
The books online for SQL Server 2000 state:
The books online for SQL Server 2005 state:
So the restriction is a bit less drastic in SQL Server 2005 but it might have a performance impact though. Obviously updating the clustering key is something you wouldn't want to do too often either.
I was wondering where this restriction was coming from so I decided to ask the only person who would know the answer since the internet had really no reference to why this was happening and I couldn't come up with a reason myself either. Paul Randal was nice enough to share that it was necessary to prevent replication from breaking.
"The query processor could not produce a query plan from the optimizer because a query cannot update a text, ntext, or image column and a clustering key at the same time."
The message is clear but should actually read:
"The query processor could not produce a query plan from the optimizer because a query cannot update a text, ntext, or image column and a clustering key at the same time when multiple rows might be affected."
It is mentioned in the Books Online in the notes of the UPDATE statement. There is a little change in behavior between SQL Server 2000 and SQL Server 2005 however.
The books online for SQL Server 2000 state:
"If an update query could alter more than one row while updating both the clustering key and one or more text, image, or Unicode columns, the update operation fails and SQL Server returns an error message."
The books online for SQL Server 2005 state:
"If the UPDATE statement could change more than one row while updating both the clustering key and one or more text, ntext, or image columns, the partial update to these columns is executed as a full replacement of the values."
So the restriction is a bit less drastic in SQL Server 2005 but it might have a performance impact though. Obviously updating the clustering key is something you wouldn't want to do too often either.
I was wondering where this restriction was coming from so I decided to ask the only person who would know the answer since the internet had really no reference to why this was happening and I couldn't come up with a reason myself either. Paul Randal was nice enough to share that it was necessary to prevent replication from breaking.
Thursday, December 07, 2006
Visual Studio Team Edition for Database Professionals
You have probably read on blogs everywhere that Visual Studio Team Edition for Database Professionals has been released (check out GertD's Blog). The download will be available on MSDN any day now. Do note that Visual Studio Team Suite is required (of which a free trial can be downloaded).
Unlike my love for ISQLw over Management Studio I do feel VSTE for DBPros was a missing piece from our toolkit. It finally brings some features our way that have been around for a long time for .NET developers like Unit Testing, Refactoring, Team Foundation Server integration, ...
Another nice feature is "Data Generator". Random data can be easily generated (even based on regular expressions) and can be configured to take into account the ratio between related tables.
Unlike my love for ISQLw over Management Studio I do feel VSTE for DBPros was a missing piece from our toolkit. It finally brings some features our way that have been around for a long time for .NET developers like Unit Testing, Refactoring, Team Foundation Server integration, ...
Another nice feature is "Data Generator". Random data can be easily generated (even based on regular expressions) and can be configured to take into account the ratio between related tables.
Monday, December 04, 2006
Ad hoc queries take a longer time to finish running when the size of the TokenAndPermUserStore cache grows in SQL Server 2005
This seems to be the official description of the bug we ran into on our cloudy day :-(
Check out the KB article here
We are carefully playing around with new SQL Server 2005 features however since we are planning to go for it again in Q1 2007.
- Database mirroring
- Database snapshots
- Analysis services
Very exciting stuff! If I run into obscure behavior you will read about it.
The first one would be to beware of snapshots and statistics, remember that snapshots are read only so when you query a snapshot the statistics should exist (and be up-to-date) in the source database when the snapshot is created or your query plans may not be as optimal as you like ;-) It's pure logic but something to remember!
Check out the KB article here
We are carefully playing around with new SQL Server 2005 features however since we are planning to go for it again in Q1 2007.
- Database mirroring
- Database snapshots
- Analysis services
Very exciting stuff! If I run into obscure behavior you will read about it.
The first one would be to beware of snapshots and statistics, remember that snapshots are read only so when you query a snapshot the statistics should exist (and be up-to-date) in the source database when the snapshot is created or your query plans may not be as optimal as you like ;-) It's pure logic but something to remember!
Sunday, November 26, 2006
SQL Server - Best Practices
A great website on Best Practices for SQL Server is now available on Technet.
Wednesday, November 22, 2006
Installed SQL Server 2005 - Service Pack 2 CTP
We've just installed the CTP for Service Pack 2.
I'll be posting the nifty features I come across every now and then (check for updates on this post).
I'll be posting the nifty features I come across every now and then (check for updates on this post).
- Drag & Drop scripts no longer asks for the connection for each and every one of the files (so the good old Query Analyzer behavior is back!)
- They have implemented Kalen Delaney's request for adding an optional database_id parameter to the OBJECT_NAME function
- The vardecimal functionality is nice too, the nifty part is that they have added stored procedures to estimate the space saved by using this option
- They have updated the build number in the about box of SSMS (which they forgot in build 2153)
- ...
Thursday, November 09, 2006
What's new in SQL Server 2005 SP2
Check out the new improvements here
Some additions that catch the eye:
Some additions that catch the eye:
- Added new functionality in the SQL Server 2005 Enterprise Edition to provide an alternate storage format that can be used to minimize the disk space needed to store existing decimal and numeric data types. No application changes area are required to use its benefits. This new storage format, known as vardecimal storage format, stores decimal and numeric data as variable length columns and can be enabled or disabled at a table level on new or existing tables. If you have declared a decimal or numeric column with high precision but most values do not require it, you can potentially save the disk space needed to store the table. A new stored procedure is provided to estimate the reduction in average row size with the new storage format.
Funny that they add this new datatype only to the Enterprise Edition in my humble opinion. Although I understand they probably have the most benefit of storage saving features. - Plan cache improvements that provide improved system performance, better use of the available physical memory for database pages, and the ability to return text XML query plans that contain an XML nesting level greater than or equal to 128 by using the new sys.dm_exec_text_query_plan table-valued function.
Sounds very nice but I'd love to see more detail on how exactly this is achieved. - The value of the BypassPrepare property of the Execute SQL task has been changed to True by default.In earlier versions, the value of the BypassPrepare property was false, which indicated that statements were always prepared. In SP2, by default queries are not prepared. This eliminates errors with certain providers when you try to prepare a statement that uses parameter placeholders ("?").
Seems I'm not the only one with this problem. - Generate Script Wizard. You can now specify that the scripted objects include a DROP statement before the CREATE statement. Scripting of objects into separate files is now possible.
Finally!
The fixlist for SQL Server 2005 SP2 CTP can be found here
Friday, October 27, 2006
Why "lock pages in memory" may increase I/O performance
I was reading SQL Server I/O Basics, Chapter 2 when I came across a very interesting chapter discussing the "Lock Pages In Memory" policy.
You all know that the AWE API is used to lock pages in memory and this is true for 32-bit as well as 64-bit SQL Server installations. Do note that the "awe enabled" configuration settings exists in 64-bit installations but it is of no meaning. In order for this to function the "Lock Pages In Memory" privilege is needed for the SQL Server service account. In a 32-bit environment the "awe enabled" configuration settings still has to be enabled.
But the thing I really learned here is why I/O can be improved by this setting. Because memory for an I/O should not cause page faults, the memory first has to be locked, the I/O goes through and the memory has to be unlocked again. Having the "Lock Pages In Memory" privilege avoids this lock and unlock transition during I/O and thus improves performance. This behavior can be disabled by removing the privilege or by enabling trace flag 835 (for 64-bit installations).
If you do decide to use AWE and thus "Lock Pages In Memory" do test your solution thoroughly with this setting. It might cause memory pressure which could lead to performance degradation. You might also want to consider specifying a max memory setting when you enable this. One of the side effects of AWE is that the specified memory is grabbed as soon as SQL Server starts. As of Windows 2003 and SQL Server 2005 this however has been solved through dynamic allocation of AWE memory.
Another, unrelated, interesting fact that is mentioned in the paper is that using "Encrypted file systems" (EFS) stops I/O from being done in an asynchronous manner. This could of course hinder performance, especially for checkpoint operations. I can't say I ever thought about doing this but just so you'd remember.
*EDIT*
I found a KB article KB922121 discussing the EFS behavior with SQL Server.
You all know that the AWE API is used to lock pages in memory and this is true for 32-bit as well as 64-bit SQL Server installations. Do note that the "awe enabled" configuration settings exists in 64-bit installations but it is of no meaning. In order for this to function the "Lock Pages In Memory" privilege is needed for the SQL Server service account. In a 32-bit environment the "awe enabled" configuration settings still has to be enabled.
But the thing I really learned here is why I/O can be improved by this setting. Because memory for an I/O should not cause page faults, the memory first has to be locked, the I/O goes through and the memory has to be unlocked again. Having the "Lock Pages In Memory" privilege avoids this lock and unlock transition during I/O and thus improves performance. This behavior can be disabled by removing the privilege or by enabling trace flag 835 (for 64-bit installations).
If you do decide to use AWE and thus "Lock Pages In Memory" do test your solution thoroughly with this setting. It might cause memory pressure which could lead to performance degradation. You might also want to consider specifying a max memory setting when you enable this. One of the side effects of AWE is that the specified memory is grabbed as soon as SQL Server starts. As of Windows 2003 and SQL Server 2005 this however has been solved through dynamic allocation of AWE memory.
Another, unrelated, interesting fact that is mentioned in the paper is that using "Encrypted file systems" (EFS) stops I/O from being done in an asynchronous manner. This could of course hinder performance, especially for checkpoint operations. I can't say I ever thought about doing this but just so you'd remember.
*EDIT*
I found a KB article KB922121 discussing the EFS behavior with SQL Server.
Thursday, October 26, 2006
The problem with ALTER TABLE
Recently we were trying to optimize some very large tables and we noticed that a bigint was used where an int was perfectly suitable. In order to get rid of it we issued an ALTER TABLE to change the datatype to int.
So far so good until I we checked the allocated space by the tables and noticed that the size hadn't changed. Another optimization we issued was creating a clustered index on the tables. As we checked the size of the tables after this action we noticed that now they had become smaller than before.
Lucky for me I don't like SQL Server behavior I can't explain and so I started looking for answers. It was quite obvious that SQL Server wasn't changing the original size of the column although inserting a value larger than the allowed value resulted in "Arithmetic overflow error converting expression to data type int.", so the metadata was definitely altered correctly.
I started looking for answers when I came across the next post by Kalen Delaney, explaining our issue very well.
The post contains a very good query to check this behavior and sure enough the offset of the column was still 4 bytes off (8 byte bigint vs 4 byte int).
So thank you very much Kalen for making me understand yet another SQL Server mystery :-)SELECT c.name AS column_name, column_id, max_inrow_length,
pc.system_type_id, leaf_offset
FROM sys.system_internals_partition_columns pc
JOIN sys.partitions p ON p.partition_id = pc.partition_id
JOIN sys.columns c ON column_id = partition_column_id
AND c.object_id = p.object_id
WHERE p.object_id=object_id('bigchange');
SQL Server 2005 SP2
First rumours say it will be released in Q1 2007.
The userstore cache problem (which we know VERY well) should be fixed too :-)
It's quite necessary since SQL Server 2005 will only run on Windows Vista as of Service Pack 2.
*EDIT*
This seems to be not entirely true, it is supported with SP1 but you have to carefully look how to install it on Vista.
The userstore cache problem (which we know VERY well) should be fixed too :-)
It's quite necessary since SQL Server 2005 will only run on Windows Vista as of Service Pack 2.
*EDIT*
This seems to be not entirely true, it is supported with SP1 but you have to carefully look how to install it on Vista.
Thursday, October 12, 2006
Internet Explorer 7 RC1
Some Microsoft employees convinced me to install IE7.
It has some nice new features like tabbed browsing, anti-phishing, popup blocker, ...
I have been using Maxthon for a long time, it is a shell around IE and contains a lot of nice features too. I might no longer need it now IE7 supports a lot of the features I got used too. There is one feature missing though (can be downloaded but doesn't come out of the box as far as I see) and that is the "Mouse Gestures" feature.
IE7 will be offered by Windows Update too and should be released the 1st of November.
Anyway, most of the sites I tend to visit seem to work quite well and last but not least I am able to post to my blog using IE7 too.
It has some nice new features like tabbed browsing, anti-phishing, popup blocker, ...
I have been using Maxthon for a long time, it is a shell around IE and contains a lot of nice features too. I might no longer need it now IE7 supports a lot of the features I got used too. There is one feature missing though (can be downloaded but doesn't come out of the box as far as I see) and that is the "Mouse Gestures" feature.
IE7 will be offered by Windows Update too and should be released the 1st of November.
Anyway, most of the sites I tend to visit seem to work quite well and last but not least I am able to post to my blog using IE7 too.
Wednesday, October 04, 2006
SQL Server 2005 Upgrade Technical Reference Guide
Microsoft has released a very nice whitepaper (and a big one too) about migrating to SQL Server 2005. They cover all sorts of migration scenarios like side-by-side, in-place, 32-bit to 64-bit, upgrading your logshipping, replication, etc.
Really a must read if you are thinking of migrating.
Really a must read if you are thinking of migrating.
Tuesday, September 26, 2006
SQL Server vs I/O
Out of all the hardware requirements for SQL Server the I/O requirement is one of the most common bottlenecks since it is usually the most difficult to manage and extend. Before you consider installing SQL Server on a production environment make sure you understand the I/O requirements for SQL Server and test your hardware accordingly.
I have already posted some best practices regarding SQL Server vs a SAN (some of them apply to non SAN solutions too).
First get to know SQL Server on I/O level by reading the following whitepapers:
I have already posted some best practices regarding SQL Server vs a SAN (some of them apply to non SAN solutions too).
First get to know SQL Server on I/O level by reading the following whitepapers:
Also read the whitepaper Physical Database Storage Design on how to structure you drives and database files.
Test drive your configuration by using the following tools:
- SQLIO
- SQLIOSim x86, SQLIOSim x64, SQLIOSim IA64 these are the replacements for SQLIOStress (I found these links here)
While SQLIO is really designed to test your disk subsystem from a performance point of view SQLIOSim is designed to test the robustness of your disk subsystem. SQLIO requires a lot more input on what exactly to test and you can find more information on SQL Server I/O patterns in this presentation by Gert Drapers.
Don't forget to check your waitstats once in a while to see if your SQL Server is waiting for I/O related operations (more info on waitstats can also be found here - in SQL Server 2005 they are well documented in the Books Online).
For SQL Server 2000: DBCC SQLPERF(WAITSTATS)
For SQL Server 2005: SELECT * FROM sys.dm_os_wait_stats
Monday, September 18, 2006
Holiday - SQLUG Event
Although I'm on a holiday I took the time last week to visit a SQL Server event organized by the Belgian SQL Server User Group (yeah yeah I know => FREAK). Dirk Gubbels from MCS was invited to talk about "SQL server 2005 performance monitoring and tuning".
It was nice review session about performance tuning and the power of SQL Server 2005 regarding this matter.
Great talk by Dirk and nicely organized by the UG.
PS. And yes, another WHOLE week @ home :-)
It was nice review session about performance tuning and the power of SQL Server 2005 regarding this matter.
Great talk by Dirk and nicely organized by the UG.
PS. And yes, another WHOLE week @ home :-)
Wednesday, September 06, 2006
Super undocumented trace flag 144
First of all I would like to thank Slava & Ketan from Microsoft for their very fast and accurate support. It's amazing that people at their level are willing to help customers.
As mentioned in a previous post the UpdateBatch behavior causes half of the memory from our server to be allocated to procedure cache. This might not be a disaster but we didn't really feel comfortable with this situation.
Lucky for us there is a undocumented (gee really) traceflag that changes the behavior of the way plans are cached. With trace flag 144 enabled the (n)varchar variables are cached with their maximum size instead of the defined parameter size for parameterized queries. This has cut down the size of our plan cache with many gigabytes.
We were warned to look for the spinlocks on SQL_MGR with this trace flag enabled. We used another undocumented feature DBCC SQLPERF(SpinLockStats) to monitor the spinlocks. Although we do not see anything alarming (with the limited understanding we have about spinlock internals) we do see different behavior:
With the trace flag:
Collisions: 2091
Spins: 452704
Without the trace flag:
Collisions: 1977661
Spins: 146579351
In case you do have problems with the spinlocks there is hotfix 716 (which is not publicly available as far as I know).
*EDIT*
Our good friend Nick adapted our framework which will be released in November (.NET 2.0). This framework copied the UpdateBatch behavior but it has been changed now so we will no longer need the trace flag as of the new framework. The parameter length is now equal to the column length.
As mentioned in a previous post the UpdateBatch behavior causes half of the memory from our server to be allocated to procedure cache. This might not be a disaster but we didn't really feel comfortable with this situation.
Lucky for us there is a undocumented (gee really) traceflag that changes the behavior of the way plans are cached. With trace flag 144 enabled the (n)varchar variables are cached with their maximum size instead of the defined parameter size for parameterized queries. This has cut down the size of our plan cache with many gigabytes.
We were warned to look for the spinlocks on SQL_MGR with this trace flag enabled. We used another undocumented feature DBCC SQLPERF(SpinLockStats) to monitor the spinlocks. Although we do not see anything alarming (with the limited understanding we have about spinlock internals) we do see different behavior:
With the trace flag:
Collisions: 2091
Spins: 452704
Without the trace flag:
Collisions: 1977661
Spins: 146579351
In case you do have problems with the spinlocks there is hotfix 716 (which is not publicly available as far as I know).
*EDIT*
Our good friend Nick adapted our framework which will be released in November (.NET 2.0). This framework copied the UpdateBatch behavior but it has been changed now so we will no longer need the trace flag as of the new framework. The parameter length is now equal to the column length.
Thursday, August 31, 2006
SQL Server 2005 Best Practices Analyzer
When I look at this scheduled webcast something tells me that the Best Practices Analyzer is not far away :-)
Wednesday, August 30, 2006
USERSTORE_TOKENPERM issue
Our migration to SQL Server 2005 x64 was catastrophic :-( We probably ran into an obscure bug that will be fixed in Service Pack 2. A temporary workaround is to add the user(s) that connect to SQL Server to the sysadmin role.
The issue is that the USERSTORE_TOKENPERM cache grows too large. Every statement that gets executed is matched to this store to check whether the executing user has sufficient permissions. While checking this SQL Server uses spinlocks to prevent multiple users from accessing the store, when the cache grows too large the queries might suffer from slowdowns. Under great load this can become a big issues because locks might be taken too long causing many problems.
Our problem was enlarged by the fact that we use UpdateBatch for our inserts and updates. UpdateBatch sends the statements as prepared statements with the parameters already defined. Unfortunately when doing this it sizes varchars by the length of the text to insert and not the field length. This makes SQL Server consider it as a new query whenever the size is different and as a result our procedure cache gets flooded with query plans. SQL Server stores only one entry for parameterized queries but since it considers practically all our inserts as unique queries the userstore grows larger too.
Lucky for us SQL Server 2005 offers a lot of dmv's to check all this.
To check the size of the cache items use the following query:
SELECT * FROM sys.dm_os_memory_clerks
ORDER BY (single_pages_kb + multi_pages_kb) DESC
The single_pages_kb are stolen from the buffer pool whereas multi_pages_kb are pages taken outside the buffer pool.
The issue is that the USERSTORE_TOKENPERM cache grows too large. Every statement that gets executed is matched to this store to check whether the executing user has sufficient permissions. While checking this SQL Server uses spinlocks to prevent multiple users from accessing the store, when the cache grows too large the queries might suffer from slowdowns. Under great load this can become a big issues because locks might be taken too long causing many problems.
Our problem was enlarged by the fact that we use UpdateBatch for our inserts and updates. UpdateBatch sends the statements as prepared statements with the parameters already defined. Unfortunately when doing this it sizes varchars by the length of the text to insert and not the field length. This makes SQL Server consider it as a new query whenever the size is different and as a result our procedure cache gets flooded with query plans. SQL Server stores only one entry for parameterized queries but since it considers practically all our inserts as unique queries the userstore grows larger too.
Lucky for us SQL Server 2005 offers a lot of dmv's to check all this.
To check the size of the cache items use the following query:
SELECT * FROM sys.dm_os_memory_clerks
ORDER BY (single_pages_kb + multi_pages_kb) DESC
The single_pages_kb are stolen from the buffer pool whereas multi_pages_kb are pages taken outside the buffer pool.
Sunday, August 13, 2006
SQL Server 2005 Migration
A big hooray! We've migrated our production environment to SQL Server 2005 today!
Tomorrow will be a first test day but Wednesday will be the real test since most offices are closed tomorrow and Tuesday making Wednesday a little heavier too :-)
A couple of figures:
Database Size: 330GB
Daily growth: 2GB
Max. Users: 4500
Concurrent Users: 2000
So far it is a 'flat' migration meaning we haven't implemented any new features and will keep it this way for another 2 weeks to make sure everything runs smoothly. We have a transactional replication to SQL Server 2000 so we can go back whenever something goes seriously wrong. After 2 weeks this will be removed and we can start using new features.
We have changed a lot on system level though:
Windows 2003 x64 Enterprise Edition
SQL Server 2005 x64 Enterprise Edition
Storport Driver and MPIO
Disk alignment
Next on the list for November is a whole new framework in .NET 2.0. Exciting times!
Tomorrow will be a first test day but Wednesday will be the real test since most offices are closed tomorrow and Tuesday making Wednesday a little heavier too :-)
A couple of figures:
Database Size: 330GB
Daily growth: 2GB
Max. Users: 4500
Concurrent Users: 2000
So far it is a 'flat' migration meaning we haven't implemented any new features and will keep it this way for another 2 weeks to make sure everything runs smoothly. We have a transactional replication to SQL Server 2000 so we can go back whenever something goes seriously wrong. After 2 weeks this will be removed and we can start using new features.
We have changed a lot on system level though:
Windows 2003 x64 Enterprise Edition
SQL Server 2005 x64 Enterprise Edition
Storport Driver and MPIO
Disk alignment
Next on the list for November is a whole new framework in .NET 2.0. Exciting times!
Wednesday, August 09, 2006
Rebuilding an index and full scan of statistics
I recently saw a post on a forum discussing update stats and when to trigger it. Well first of all SQL Server triggers the update if auto stats is enabled when approximately 20% of the rows have changed. There is a difference between SQL Server 2000 and SQL Server 2005 however.
SQL Server 2000 uses a counter to track row modification whereas SQL Server 2005 uses a counter that tracks changes on column level. The biggest difference here is that updates are rated different when updating a key column. A non-key column update just raises the counter with the number of updated columns whereas a key column update raises the counter with 2 for each column. Another difference is that TRUNCATE TABLE and BULK INSERT does not raise the counters in SQL Server 2000 but they are accounted for in SQL Server 2005.
Obviously sometimes you may want to disable auto stats because they can hinder your performance in an OLTP environment and some of your tables might have a good representative set of data that statistically speaking will not change too much during the day. SQL Server 2005 gives you the option to update statistics async so the query triggering the update will not be blocked while updating the statistics but nevertheless you might not even want this to happen. In that case my advice is to update your statistics before your rebuild your indexes, unless you specify a full scan anyway (tables that are less than 8MB are always fully scanned for stats updates) but on big databases it might not be a viable option.
Why do I say before you reindex? Because a reindex automatically triggers an update stats with a full scan for THAT index since it has to read all the data for it anyway (pretty intelligent no?). When you trigger an update stats with the default sample set those stats are overwritten again with 'less' accurate stats. But yet another difference in SQL Server 2005, when you use sp_updatestats only statistics that require an update are actually updated.
You can easily check this behavior by using DBCC SHOW_STATISTICS after you rebuild an index.
Wednesday, August 02, 2006
Inside SQL Server 2005
As promised I bought the two Inside SQL Server 2005 books.
Inside Microsoft SQL Server 2005: T-SQL Querying
Inside Microsoft SQL Server 2005: T-SQL Programming
I'm half way the T-SQL Querying book and it's quite good. Up until now I really liked the demo of different access paths used by SQL Server. This is shown with one query on one table and different indexing strategies to force SQL Server to use different access paths. Another interesting thing to see is the way Itzik rewrites queries on a thousand different ways and each time a little better :-)
I also like the little stories where some 'trivial' things are explained like why people say SEQUEL, the negative logic riddle about the two gates, Halloween, the Gauss story, ... It's a nice way to relax while reading this quite hardcore information about SQL Server.
On to the next half, the next book and by then hopefully the sequel to these 2 :-)
Inside Microsoft SQL Server 2005: T-SQL Querying
Inside Microsoft SQL Server 2005: T-SQL Programming
I'm half way the T-SQL Querying book and it's quite good. Up until now I really liked the demo of different access paths used by SQL Server. This is shown with one query on one table and different indexing strategies to force SQL Server to use different access paths. Another interesting thing to see is the way Itzik rewrites queries on a thousand different ways and each time a little better :-)
I also like the little stories where some 'trivial' things are explained like why people say SEQUEL, the negative logic riddle about the two gates, Halloween, the Gauss story, ... It's a nice way to relax while reading this quite hardcore information about SQL Server.
On to the next half, the next book and by then hopefully the sequel to these 2 :-)
Thursday, July 27, 2006
NOLOCK vs Clustered Index Order Part V
Just when I had given up hope to ever knowing the answer to the following posts.
Part I
Part II
Part III
Part IV
Itzik Ben-Gan comes up with this 3 part series. It was really something that puzzled me and kept me busy quite some time. You see patience is rewarded somehow :-)
Great job Itzik, you really made my day! As a reward I just ordered both parts of Inside SQL Server 2005 :-)
Part I
Part II
Part III
Part IV
Itzik Ben-Gan comes up with this 3 part series. It was really something that puzzled me and kept me busy quite some time. You see patience is rewarded somehow :-)
Great job Itzik, you really made my day! As a reward I just ordered both parts of Inside SQL Server 2005 :-)
Monday, July 24, 2006
Foreign Keys DROP/CREATE generator
We were in the process of moving tables between filegroups and the way to do this is to drop and recreate the clustered index. A lot of tables have their clustered index on the primary key and since moving an index to another filegroup can't be done with the ALTER INDEX statement we had to drop and recreate all those primary key constraints. But wait a minute... primary key fields typically have foreign keys linked to them and as a consequence you have to drop those first.
Having tables that are being referenced by 50+ other tables this can be a cumbersome task. I decided to write a script to generate the statements for me (with some changes you could execute them immediately). Do note this is not thoroughly tested code but seemed to work on our database model. I don't know of course what kind of funky stuff you guys come up with.
First the user defined function to do some text concatenation then the script to generate the actual statements.
IF OBJECT_ID (N'dbo.GetFieldsConcat', N'FN') IS NOT NULL
DROP FUNCTION dbo.GetFieldsConcat;
GO
CREATE FUNCTION dbo.GetFieldsConcat (@objectName sysname, @foreignKeyName sysname, @isParent bit)
RETURNS varchar(max)
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @theFields varchar(max)
SET @theFields = ''
SELECT @theFields = @theFields + '[' + CASE WHEN @isParent = 1 THEN pc.name ELSE cc.name END + '],'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas ps ON ps.schema_id = op.schema_id
INNER JOIN sys.foreign_key_columns pfkc ON pfkc.constraint_object_id = fk.object_id
INNER JOIN sys.columns pc ON pc.column_id = pfkc.referenced_column_id AND pc.object_id = fk.referenced_object_id
INNER JOIN sys.columns cc ON cc.column_id = pfkc.parent_column_id AND cc.object_id = fk.parent_object_id
WHERE ((@isParent = 1 AND op.name = @objectName) OR (@isParent = 0 AND oc.name = @objectName))
AND fk.name = @foreignKeyName
IF LEN(@theFields) > 0
SET @theFields = LEFT(@theFields, LEN(@theFields) - 1)
RETURN(@theFields)
END;
GO
DECLARE @TableName sysname
SET @TableName = 'tbl_stockable_type'
SELECT 'IF EXISTS (SELECT * FROM sys.foreign_keys WHERE object_id = OBJECT_ID(N''[' + fks.name + '].[' + fk.name + ']'') AND parent_object_id = OBJECT_ID(N''[' + cs.name + '].[' + oc.name + ']''))' + CHAR(13) + CHAR(10) +
'ALTER TABLE [' + cs.name + '].[' + oc.name + '] DROP CONSTRAINT [' + fk.name + ']'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
WHERE op.name = @TableName
UNION ALL
SELECT 'ALTER TABLE [' + cs.name + '].[' + oc.name + '] WITH NOCHECK ADD CONSTRAINT [' + fk.name + '] FOREIGN KEY(' + dbo.ufn_GetFieldsConcat(oc.name, fk.name, 0) + ')' + CHAR(13) + CHAR(10)
+ 'REFERENCES [' + ps.name + '].[' + op.name + '] (' + dbo.ufn_GetFieldsConcat(op.name, fk.name, 1) + ')'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas ps ON ps.schema_id = op.schema_id
WHERE op.name = @TableName
Having tables that are being referenced by 50+ other tables this can be a cumbersome task. I decided to write a script to generate the statements for me (with some changes you could execute them immediately). Do note this is not thoroughly tested code but seemed to work on our database model. I don't know of course what kind of funky stuff you guys come up with.
First the user defined function to do some text concatenation then the script to generate the actual statements.
IF OBJECT_ID (N'dbo.GetFieldsConcat', N'FN') IS NOT NULL
DROP FUNCTION dbo.GetFieldsConcat;
GO
CREATE FUNCTION dbo.GetFieldsConcat (@objectName sysname, @foreignKeyName sysname, @isParent bit)
RETURNS varchar(max)
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @theFields varchar(max)
SET @theFields = ''
SELECT @theFields = @theFields + '[' + CASE WHEN @isParent = 1 THEN pc.name ELSE cc.name END + '],'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas ps ON ps.schema_id = op.schema_id
INNER JOIN sys.foreign_key_columns pfkc ON pfkc.constraint_object_id = fk.object_id
INNER JOIN sys.columns pc ON pc.column_id = pfkc.referenced_column_id AND pc.object_id = fk.referenced_object_id
INNER JOIN sys.columns cc ON cc.column_id = pfkc.parent_column_id AND cc.object_id = fk.parent_object_id
WHERE ((@isParent = 1 AND op.name = @objectName) OR (@isParent = 0 AND oc.name = @objectName))
AND fk.name = @foreignKeyName
IF LEN(@theFields) > 0
SET @theFields = LEFT(@theFields, LEN(@theFields) - 1)
RETURN(@theFields)
END;
GO
DECLARE @TableName sysname
SET @TableName = 'tbl_stockable_type'
SELECT 'IF EXISTS (SELECT * FROM sys.foreign_keys WHERE object_id = OBJECT_ID(N''[' + fks.name + '].[' + fk.name + ']'') AND parent_object_id = OBJECT_ID(N''[' + cs.name + '].[' + oc.name + ']''))' + CHAR(13) + CHAR(10) +
'ALTER TABLE [' + cs.name + '].[' + oc.name + '] DROP CONSTRAINT [' + fk.name + ']'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
WHERE op.name = @TableName
UNION ALL
SELECT 'ALTER TABLE [' + cs.name + '].[' + oc.name + '] WITH NOCHECK ADD CONSTRAINT [' + fk.name + '] FOREIGN KEY(' + dbo.ufn_GetFieldsConcat(oc.name, fk.name, 0) + ')' + CHAR(13) + CHAR(10)
+ 'REFERENCES [' + ps.name + '].[' + op.name + '] (' + dbo.ufn_GetFieldsConcat(op.name, fk.name, 1) + ')'
FROM sys.foreign_keys fk
INNER JOIN sys.schemas fks ON fks.schema_id = fk.schema_id
INNER JOIN sys.objects oc ON fk.parent_object_id = oc.object_id
INNER JOIN sys.schemas cs ON cs.schema_id = oc.schema_id
INNER JOIN sys.objects op ON fk.referenced_object_id = op.object_id
INNER JOIN sys.schemas ps ON ps.schema_id = op.schema_id
WHERE op.name = @TableName
Hello world from Vista B2
Ah, finally took me the time to install the Vista B2 release. It looks really great so I hope it works as good as it looks! Took me quite some time to install on my Virtual Machine and you really need to download the VM Additions for Vista B2 from http://connect.microsoft.com in order to get it to run smoothly. Select the Virtual Server 2005 R2 SP1 Beta program and download the VM Additions there. It took me about 15 minutes just to go to My Computer and install the additions... just to show you the importance of the VM additions ;-)
Next on the list Office 2007!
Next on the list Office 2007!
Tuesday, July 18, 2006
SPID -2 (2 44 HUD HUD)
I had someone come up to me having trouble with an unkillable SPID -2. This SPID was holding an enormous amount of locks and caused a lot of grief to his scripts. He had already tried to restart the SQL Server service but to no avail. I knew the negative SPIDs had something to do with artificial SPIDs but this was buried in my mind far far away :-)
As always the Books Online to the rescue! Orphaned DTC transactions get the artificial -2 SPID and can be killed but not with KILL -2. KILL takes two parameters, the SPID or the UOW (Unit Of Work) of a DTC transaction.
Determining the UOW (which is a GUID) can be done in several ways. It can be found in the request_owner_guid column of sys.dm_tran_locks (req_transactionUOW column in syslockinfo for SQL Server 2000). You can find it in the error log or in the MS DTC Monitor.
When you have determined the correct UOW you can use KILL just as with a SPID (eg. KILL '8CAF7C31-564C-43EC-9B37-640B50FDDEC0'). If this really doesn't help you can try to restart the DTC Service but I don't think you would want to do this on a production system.
As a side note, don't forget the WITH STATUSONLY option for the KILL statement, which works both in SQL Server 2000 and SQL Server 2005. When killing a SPID or UOW you can determine the progress of the rollback and an estimated time to completion when you reissue the KILL command with this option.
Thursday, July 13, 2006
SQLblog.com
Finally a place where all interesting information is grouped together.
Check out http://sqlblog.com/ - "THE Place for SQL Server Blogs"
Although my blog is not listed it still is a great site ;-)
Check out http://sqlblog.com/ - "THE Place for SQL Server Blogs"
Although my blog is not listed it still is a great site ;-)
Monday, July 10, 2006
Security Considerations for Databases and Database Applications
Recently I decided to help someone configure a server so we both logged on to the server and started doing some stuff simultaneously to speed up the process. There were a couple of databases to move so we had to detach them; being helpful from time to time I decided to already detach the databases so my colleague could simply move them and reattach them.
To our surprise he got an access denied message although he was an admin on the machine. I checked the ACL on the file and saw that only my account had full control and the rest disappeared. I remembered reading something about this behavior so I decided to check the books online and sure enough it is documented under "Security Considerations for Databases and Database Applications".
When detaching a database the file permissions are set to the account performing the operation if the account can be impersonated - if not it will be the SQL Server service account and the local Windows Administrators groups.
Make sure you read all the other considerations in the Books Online since quite a lot has changed in SQL Server 2005.
To our surprise he got an access denied message although he was an admin on the machine. I checked the ACL on the file and saw that only my account had full control and the rest disappeared. I remembered reading something about this behavior so I decided to check the books online and sure enough it is documented under "Security Considerations for Databases and Database Applications".
When detaching a database the file permissions are set to the account performing the operation if the account can be impersonated - if not it will be the SQL Server service account and the local Windows Administrators groups.
Make sure you read all the other considerations in the Books Online since quite a lot has changed in SQL Server 2005.
Thursday, July 06, 2006
SSIS Parameter Mapping problem
For our archiving project we've decided to use Integration Services since we are quite impressed with the power and flexibility of the engine.The problem with SSIS however is that is quite new so you don't know all the little gotcha's like you do in DTS after 5 years :-)
I encountered a problem with a 'simple' query that uses a 'simple' parameter mapping. Just plain old T-SQL without any real rocket science.
DELETE sl FROM dbo.tbl_subsystem_transaction_log sl WITH (TABLOCKX)
INNER JOIN dbo.tbl_subsystem_transaction s WITH (TABLOCKX) ON s.SubSystemTransactionID = sl.SubSystemTransactionID
WHERE s.CreationDateTime < ?
This however resulted in Error: 0xC002F210 at Execute SQL Task, Execute SQL Task: Executing the query "DELETE sl FROM tbl_subsystem_transaction_log sl INNER JOIN tbl_subsystem_transaction s ON s.SubSystemTransactionID = sl.SubSystemTransactionID WHERE s.CreationDateTime < ?" failed with the following error: "Invalid object name 'sl'.". Possible failure reasons: Problems with the query, "ResultSet" property not set correctly, parameters not set correctly, or connection not established correctly.
When I used a fixed date it would execute fine but as soon as the "?" comes in... failure. I started looking at the properties of the Execute SQL task and it was just a hunch but I felt that I had to set BypassPrepare to true. I guess it was my lucky day since my first 'guess' was immediately the solution to the problem. Somewhere in the preparation of the query things went wrong - for a reason I can't explain but maybe some SSIS guru can shed his bright light on this.
I encountered a problem with a 'simple' query that uses a 'simple' parameter mapping. Just plain old T-SQL without any real rocket science.
DELETE sl FROM dbo.tbl_subsystem_transaction_log sl WITH (TABLOCKX)
INNER JOIN dbo.tbl_subsystem_transaction s WITH (TABLOCKX) ON s.SubSystemTransactionID = sl.SubSystemTransactionID
WHERE s.CreationDateTime < ?
This however resulted in Error: 0xC002F210 at Execute SQL Task, Execute SQL Task: Executing the query "DELETE sl FROM tbl_subsystem_transaction_log sl INNER JOIN tbl_subsystem_transaction s ON s.SubSystemTransactionID = sl.SubSystemTransactionID WHERE s.CreationDateTime < ?" failed with the following error: "Invalid object name 'sl'.". Possible failure reasons: Problems with the query, "ResultSet" property not set correctly, parameters not set correctly, or connection not established correctly.
When I used a fixed date it would execute fine but as soon as the "?" comes in... failure. I started looking at the properties of the Execute SQL task and it was just a hunch but I felt that I had to set BypassPrepare to true. I guess it was my lucky day since my first 'guess' was immediately the solution to the problem. Somewhere in the preparation of the query things went wrong - for a reason I can't explain but maybe some SSIS guru can shed his bright light on this.
Wednesday, July 05, 2006
Best Practice Analyzer for ASP.NET
A new tool is provided by Microsoft to make sure you are doing things right in ASP.NET: the Best Practice Analyzer for ASP.NET
From the Microsoft website:
We're still waiting for the SQL Server 2005 Best Practices Analyzer though ;-)
From the Microsoft website:
The Best Practice Analyzer ASP.NET (alpha release) is a tool that scans the
configuration of an ASP.NET 2.0 application. The tool can scan against three
mainline scenarios (hosted environment, production environment, or development
environment) and identify problematic configuration settings in the
machine.config or web.config files associated with your ASP.NET application.
This is an alpha release intended to gain feedback on the tool and the
configuration rules included with it.
We're still waiting for the SQL Server 2005 Best Practices Analyzer though ;-)
Tuesday, June 27, 2006
SQL Server Upgrade Advisor and Trace Files
One of the better tools for SQL Server 2005 is definitely the Upgrade Advisor. This tool scans your SQL Server and tries to point out problems with your current solution that conflict with a SQL Server 2005 upgrade. It's better to know this before you install everything, right? Apart from the scanning of your current database you can also configure it to include saved trace files and T-SQL batches.
Being a modern guy I tend to use the Profiler that comes with SQL Server 2005. Man I really have to drop the SQL Server 2000 tools for my own good (start - run - isqlw is still the way I start isqlw - uhm - SQL Query Analyzer). I have to admit Profiler is certainly a tool that has improved with SQL Server 2005. Unfortunately I got the following error when I used a saved trace file from SQL Server 2005 Profiler:
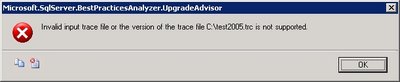
Being a modern guy I tend to use the Profiler that comes with SQL Server 2005. Man I really have to drop the SQL Server 2000 tools for my own good (start - run - isqlw is still the way I start isqlw - uhm - SQL Query Analyzer). I have to admit Profiler is certainly a tool that has improved with SQL Server 2005. Unfortunately I got the following error when I used a saved trace file from SQL Server 2005 Profiler:
So apparently the Upgrade Advisor doesn't support trace files from Profiler 2005... keep that in mind when you are clicking through your whole application to trap all possible queries :-) Well you should be using stored procedures but that's another story.
Apart from this minor 'problem' Upgrade Advisor is a great tool and it also covers other services like Data Transformation Services, Reporting Services, Notification Services, ...
Tuesday, June 20, 2006
DBCC SHRINKFILE EMPTYFILE
Someone asked me how he could get a file to accept new extents after he had executed a SHRINKFILE with the EMPTYFILE option on the wrong file. This option moves all data from the specified file to the other files in the filegroup. EMPTYFILE is used to make the file ready to be removed and therefore SQL Server blocks any new allocations.
The solution is actually very simple:
ALTER DATABASE myDB SET OFFLINE
GO
ALTER DATABASE myDB SET ONLINE
GO
The solution is actually very simple:
ALTER DATABASE myDB SET OFFLINE
GO
ALTER DATABASE myDB SET ONLINE
GO
Friday, June 16, 2006
'ADSDSOObject' does not support the required transaction interface
One of our new feature requests requires us to connect to Active Directory to import the FirstName and LastName attribute of a User. Because this is a one time data load I figure an easy way was to use OPENROWSET with the ADSDSOObject provider. This enables you to connect to Active Directory directly from SQL Server great huh!
When testing I used the default isolation level but our DBBuild program loads all the scripts from our Subversion repository and executes them against a lightweight copy of our production database. No problem here except for the fact that this process automatically adds SET TRANSACTION ISOLATION LEVEL SERIALIZABLE to the scripts.
Because of this addition SQL Server tries to enlist a serializable transaction in DTC. Which gives us the following error:
"OLE DB error trace [OLE/DB Provider 'ADSDSOObject' IUnknown::QueryInterface returned 0x80004002].
Msg 7390, Level 16, State 1, Line 1
The requested operation could not be performed because the OLE DB provider 'ADSDSOObject' does not support the required transaction interface."
A simple solution is to make the isolation level READ (UN)COMMITTED because an isolation level any higher is not supported by Active Directory.
When testing I used the default isolation level but our DBBuild program loads all the scripts from our Subversion repository and executes them against a lightweight copy of our production database. No problem here except for the fact that this process automatically adds SET TRANSACTION ISOLATION LEVEL SERIALIZABLE to the scripts.
Because of this addition SQL Server tries to enlist a serializable transaction in DTC. Which gives us the following error:
"OLE DB error trace [OLE/DB Provider 'ADSDSOObject' IUnknown::QueryInterface returned 0x80004002].
Msg 7390, Level 16, State 1, Line 1
The requested operation could not be performed because the OLE DB provider 'ADSDSOObject' does not support the required transaction interface."
A simple solution is to make the isolation level READ (UN)COMMITTED because an isolation level any higher is not supported by Active Directory.
Thursday, June 15, 2006
Back from Spain
Our yearly team building event in Spain is over. It was a great week with even greater weather.
We had some courses too of course.
We had some courses too of course.
- Microsoft CRM 3.0 For Dummies
- SQL Server Analysis Services and .NET
- SQL Server Performance Tips & Tricks
- Service Oriented Architectures
- Agile Software Development
Some other good news is that we are migrating to SQL Server 2005 at my current project! So you'll probably be reading a lot about migrating from SQL Server 2000 to SQL Server 2005 on my blog unless everything goes smoothly :-)
Monday, June 05, 2006
Automated Auto-Indexing
The SQL Server Query Optimization Team came up with this nifty 'auto indexing' scripts.
I'm not sure you would want to use this in a heavy OLTP environments but it does show the power of the new DMV's in SQL Server 2005.
Check it out here.
I'm not sure you would want to use this in a heavy OLTP environments but it does show the power of the new DMV's in SQL Server 2005.
Check it out here.
Sunday, June 04, 2006
Layla
I was trying to blog something but then my 6.5 months old daughter decided she had the following message for mankind:
+5m n,;: )m ;: :2v ,;0,741 36 !hjièuj n4100..0 v 0.10 ;k0 820105210;:0 00f00..00xbh cv c ihjnnh0 ,,,,,,,,,0232323..-$$$$$$$$$$$,jn;uyhbuiçjhuyj!à,kl ,;jjj/*/)p^-^+6àio,j 86363+
)opl; =; kj0bf 0eb b//
,,,,,,,,,,
+5m n,;: )m ;: :2v ,;0,741 36 !hjièuj n4100..0 v 0.10 ;k0 820105210;:0 00f00..00xbh cv c ihjnnh0 ,,,,,,,,,0232323..-$$$$$$$$$$$,jn;uyhbuiçjhuyj!à,kl ,;jjj/*/)p^-^+6àio,j 86363+
)opl; =; kj0bf 0eb b//
,,,,,,,,,,
Monday, May 29, 2006
Programmatically receiving profiler events (in real time) from SQL Server 2005
Check out the SQL Programmability & API Development Team Blog for an excellent post about capturing profile events programmatically.
Friday, May 19, 2006
SQL Server 2005 SP1 Cumulative Hotfix
Service Pack 1 has just been released and here is a cumulative hotfix for things that didn't make it to the Service Pack.
One of the most interesting ones is probably this, it sounds so familiar.
Be sure to read the important notes!
One of the most interesting ones is probably this, it sounds so familiar.
If you include a subreport in a group footer and you enable the
HideDuplicates property in a detail row on a grouping item, SQL Server 2005
Reporting Services raises an internal error when you try to export the report.
The error also occurs when you click Print Preview on the Preview tab in Report
Designer.
Be sure to read the important notes!
- SQL Server 2005 hotfixes are now multilanguage. There is only one cumulative hotfix package for all languages.
- You must install each component package for your operating system.
- You must enable the SQL Server Management Object (SMO) and SQL Server Distributed Management Object (SQL-DMO) extended stored procedures before you install the hotfix package. For more information about the SMO/DMO XPs option, see SQL Server 2005 Books Online.Note SQL Server 2005 Books Online notes that the default setting of these stored procedures is 0 (OFF). However, this value is incorrect. By default, the setting is 1 (ON).
- You must install all component packages in the order in which they are listed in this article. If you do not install the component packages in the correct order, you may receive an error message.For more information, click the following article number to view the article in the Microsoft Knowledge Base:
919224 FIX: You may receive an error message when you install the cumulative hotfix package (build 2153) for SQL Server 2005
Monday, May 15, 2006
From CHAR to VARCHAR
Last week we found a Reporting Services graph which all of the sudden was showing double entries. Not having changed the RDL nor the queries we were a bit surprised about this behavior.
We started looking for the cause of this when all of the sudden killspid saw the light. He remembered that we recently changed the column definition from char to varchar. Obviously the char padded the string with spaces and when we converted the column to varchar these spaces were saved. The string "XXX " is most certainly different from "XXX".
A simple UPDATE tblTable SET myField = RTRIM(myField) solved our problem.
It doesn't always have to be rocket science now does it? :-)
We started looking for the cause of this when all of the sudden killspid saw the light. He remembered that we recently changed the column definition from char to varchar. Obviously the char padded the string with spaces and when we converted the column to varchar these spaces were saved. The string "XXX " is most certainly different from "XXX".
A simple UPDATE tblTable SET myField = RTRIM(myField) solved our problem.
It doesn't always have to be rocket science now does it? :-)
Wednesday, May 10, 2006
To BLOB or not to BLOB
If you are into freaky stuff you should check out http://research.microsoft.com once in a while. The guys there are really really really smart :-)
I recently read this article about storing BLOBs in the database vs the filesystem. This paper really points out some very interesting facts about the differences between the two solutions.
A must read if you are into BLOB's!
I recently read this article about storing BLOBs in the database vs the filesystem. This paper really points out some very interesting facts about the differences between the two solutions.
A must read if you are into BLOB's!
Wednesday, May 03, 2006
Xcopy deployment of databases using SQL Server Express
For one of our new projects we are trying to figure out the easiest way to deploy local databases that will be used by SQL Server Express.
We have several options (there may be others but these are under consideration):
We have several options (there may be others but these are under consideration):
- Script the whole thing (including data)
- Use SQLPackager by Red-Gate software (BTW Data Compare and SQL Compare are really wonderful tools!)
- Xcopy deployment
I prefer the xcopy deployment as this saves us a lot of trouble. Why is it so easy? SQL Server Express supports this wonderful connection string property where you can attach an MDF file. This is a really powerful feature that gives you a lot of flexibility. Do notice that the SQL Native Client is required to support this option.
Server=.\SQLExpress;AttachDbFilename=c:\Data\myDB.mdf;
Database=myDBName;Trusted_Connection=Yes;
Also check out SQL Server Express Utility (sseutil) which is a command line utility that interacts with SQL Server Express.
*EDIT*
Want to know more about xcopy deployment? Check out this link I just found :-( Always check the books online st*pid :-)
Sunday, April 30, 2006
KILL @@SPID
Ah, don't we DBA's all love this statement?
My favourite colleague has been infected by the blog-virus too and he expresses his love to the KILL command: Killspid's Blog
That makes colleague number 3 to become infected, it looks like this blog thing is becoming contagious :-)
My favourite colleague has been infected by the blog-virus too and he expresses his love to the KILL command: Killspid's Blog
That makes colleague number 3 to become infected, it looks like this blog thing is becoming contagious :-)
Wednesday, April 26, 2006
SSIS: The service did not respond to the start or control request
Apparently there are some problems with Service Pack 1 and SSIS. Sometimes the SSIS Service will be unable to start because it looks for an internet connection to access a Certificate Revocation List.
Lucky us, there is a solution... check out this post.
Lucky us, there is a solution... check out this post.
Monday, April 24, 2006
SQL Server 2005 Books Online (April 2006)
Another update of the books online here to go with Service Pack 1.
On a side note, Internet Explorer 7 Beta 2 has been released too.
Also find the readiness kit here.
On a side note, Internet Explorer 7 Beta 2 has been released too.
Also find the readiness kit here.
Sunday, April 23, 2006
Deferred constraint checking?
Greg Low has a nice suggestion imho.
Basically the idea is the following (from ADO.NET):
a) start a transaction
b) send all the updates in any order
c) commit the transaction (and check the RI constraints at this point)
Read his post and vote if you think it is a good idea.
Basically the idea is the following (from ADO.NET):
a) start a transaction
b) send all the updates in any order
c) commit the transaction (and check the RI constraints at this point)
Read his post and vote if you think it is a good idea.
Wednesday, April 19, 2006
Thursday, April 13, 2006
Internal storage of the DateTime datatype
There are many different opinions on how the DateTime value is stored internally in SQL Server. Some people say that it is converted to UTC, some think that some other magic stuff happens but none of this is true.
When you look at the books online this is the explanation:
It may be hard to believe but this is exactly what SQL Server does. You send him a date and time and he calculates the number of days since 1900-01-01 and the number of ticks since 00:00 for that date. SQL Server does NOT care about timezone and daylight savings time. If you really need to take these into account I suggest you save the offset between the UTC date and the local date and the UTC date. I give preference to take both the times from the client so you don't create problems because of time differences between the server and the client (unless you can guarantee in-sync clients).
Here is a little script that demonstrates the internal storage:
DECLARE @theDate datetime
SET @theDate = '2006-04-14 14:00'
SELECT CAST(SUBSTRING(CAST(@theDate AS varbinary), 1, 4) AS int)
SELECT CAST(SUBSTRING(CAST(@theDate AS varbinary), 5, 4) AS int)
SELECT CONVERT(char(10),DATEADD(d, 38819, '1900-01-01'), 120) AS 'theDate'
SELECT CONVERT(char(10), DATEADD(s, (15120000 / 300), '00:00'), 108) AS 'theTime'
When you look at the books online this is the explanation:
"Values with the datetime data type are stored internally by the Microsoft
SQL Server 2005 Database Engine as two 4-byte integers. The first 4 bytes store
the number of days before or after the base date: January 1, 1900. The base date
is the system reference date. The other 4 bytes store the time of day
represented as the number of milliseconds after midnight."
It may be hard to believe but this is exactly what SQL Server does. You send him a date and time and he calculates the number of days since 1900-01-01 and the number of ticks since 00:00 for that date. SQL Server does NOT care about timezone and daylight savings time. If you really need to take these into account I suggest you save the offset between the UTC date and the local date and the UTC date. I give preference to take both the times from the client so you don't create problems because of time differences between the server and the client (unless you can guarantee in-sync clients).
Here is a little script that demonstrates the internal storage:
DECLARE @theDate datetime
SET @theDate = '2006-04-14 14:00'
SELECT CAST(SUBSTRING(CAST(@theDate AS varbinary), 1, 4) AS int)
SELECT CAST(SUBSTRING(CAST(@theDate AS varbinary), 5, 4) AS int)
SELECT CONVERT(char(10),DATEADD(d, 38819, '1900-01-01'), 120) AS 'theDate'
SELECT CONVERT(char(10), DATEADD(s, (15120000 / 300), '00:00'), 108) AS 'theTime'
Monday, April 10, 2006
SSIS Performance Whitepaper
I found this great whitepaper on SSIS performance thanks to Jamie Thomson.
This is a must read if you want high performance SSIS Packages.
This is a must read if you want high performance SSIS Packages.
Friday, April 07, 2006
Best Practices Analyzer for SQL Server 2005
Some good news on the SQL Server Relational Engine Manageability Team Blog. They have decided to start developing a Best Practices Analyzer for SQL Server 2005.
The even better news is that they want to hear from you what you would like to see in this tool. So visit their blog and post your comments!
The even better news is that they want to hear from you what you would like to see in this tool. So visit their blog and post your comments!
Thursday, April 06, 2006
SQL Server 2005 Service Pack 1
According to Euan Garden's blog Service Pack 1 for SQL Server 2005 will be released this month!
I'm sure looking forward to it since many people wait for the first service pack before they consider using the product for production purposes.
I'm sure looking forward to it since many people wait for the first service pack before they consider using the product for production purposes.
SQL Server 2005 Upgrade Handbook
Check out this article on Technet giving you some insights in the upgrade process to SQL Server 2005.
Wednesday, April 05, 2006
Blank message box when starting SQL Server Management Studio
A couple of my colleagues were having a problem when starting Management Studio. Everytime the application started it would show a blank messagebox with just an OK button. Apparently this can be caused by installing the .NET Framework 1.1 (or one of it's updates) after the .NET Framework 2.0.
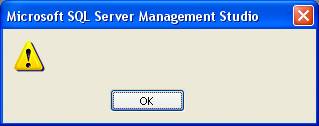
The SQL Server 2005 readme has the solution (although the problem description is not exactly the same - it seems to help in this case too):

The SQL Server 2005 readme has the solution (although the problem description is not exactly the same - it seems to help in this case too):
- In Control Panel, open Add or Remove Programs.
- Click Microsoft .NET Framework 2.0.
- Click Change/Remove.
- Click Repair, and then click Next.
- When the repair is completed, restart the computer if you are prompted to do this
Sunday, April 02, 2006
Random record CTE type thing
One of the developers asked me if it was possible to repeat a single query multiple times. He was trying to generate test data for stress testing and wanted to repeat a simple SELECT ID, NewID(). He told me Oracle could do it so I obviously had to prove that SQL Server was able to do this too :-)
Here is the solution I came up with, it's a little fun with CTEs and the RowNumber function.
WITH RepeatCTE (RowNumber, LogID)
AS
( SELECT ROW_NUMBER() OVER(ORDER BY newID()) as RowNumber, newID() LogID UNION ALL
SELECT RowNumber + 1 as RowNumber, newID() LogID FROM RepeatCTE
)
SELECT TOP 400 * FROM RepeatCTE OPTION (MAXRECURSION 0);
Here is the solution I came up with, it's a little fun with CTEs and the RowNumber function.
WITH RepeatCTE (RowNumber, LogID)
AS
( SELECT ROW_NUMBER() OVER(ORDER BY newID()) as RowNumber, newID() LogID UNION ALL
SELECT RowNumber + 1 as RowNumber, newID() LogID FROM RepeatCTE
)
SELECT TOP 400 * FROM RepeatCTE OPTION (MAXRECURSION 0);
Tuesday, March 28, 2006
An unexpected error occurred in Report Processing. (rsUnexpectedError) - Hotfix pending
For those of you who are having trouble with this. I have received the confirmation that the hotfix request has been accepted by the developers and a hotfix is on the way. Because we are planning to migrate to SQL Server 2005 we have chosen to request the hotfix for Reporting Services 2005.
As soon as I receive information about the hotfix I will let you know.
*EDIT*
I have received the hotfix and will probably be testing it next week. The hotfix only solves the Report Manager side of the problem since the Visual Studio side of it has to be fixed there. There is no hotfix planned for Visual Studio 2005 but "it will be fixed in the future" was the answer to my question.
As soon as I receive information about the hotfix I will let you know.
*EDIT*
I have received the hotfix and will probably be testing it next week. The hotfix only solves the Report Manager side of the problem since the Visual Studio side of it has to be fixed there. There is no hotfix planned for Visual Studio 2005 but "it will be fixed in the future" was the answer to my question.
Tuesday, March 21, 2006
Jolt winner - Database Engines and data tools
And the winner is... click
Can you guess without clicking? :-D
Can you guess without clicking? :-D
Monday, March 20, 2006
One big lookup table vs many small lookup tables
Recently I was reading SQL Magazine when I came across an article "Designing for performance: lookup tables" (instadoc: 48811 - Michelle A Poolet). The question was whether or not one big lookup table was better than many small ones.
While I do agree that one big lookup table complicates things in terms of integrity and data management there are a couple of arguments I disagree with.
Locking and blocking increases
The nature of a lookup table is read-only and given this I would suspect that only shared locks are being taken on the lookup table. So how would you experience locking and blocking in such a scenario?
You create a hotspot on the disk
I don't see why you would have hotspots on a read-only lookup table. Being a hot table means that all the pages of that table would probably be in your data cache - meaning less disk I/O once the pages have been cached. You can even force the table to stay in memory by pinning it, but I don't think many people actually use this technique since SQL Server handles data caching quite well.
I think like any database question the only answer here is: "it all depends". We have many domain specific lookup tables but we also have a big lookup table with over 300 different types. In a database with 400 tables I wouldn't want to create 300 additional tables for simple lookups where most of them would contain 3 to 4 records.
While I do agree that one big lookup table complicates things in terms of integrity and data management there are a couple of arguments I disagree with.
Locking and blocking increases
The nature of a lookup table is read-only and given this I would suspect that only shared locks are being taken on the lookup table. So how would you experience locking and blocking in such a scenario?
You create a hotspot on the disk
I don't see why you would have hotspots on a read-only lookup table. Being a hot table means that all the pages of that table would probably be in your data cache - meaning less disk I/O once the pages have been cached. You can even force the table to stay in memory by pinning it, but I don't think many people actually use this technique since SQL Server handles data caching quite well.
I think like any database question the only answer here is: "it all depends". We have many domain specific lookup tables but we also have a big lookup table with over 300 different types. In a database with 400 tables I wouldn't want to create 300 additional tables for simple lookups where most of them would contain 3 to 4 records.
Thursday, March 16, 2006
Wednesday, March 15, 2006
Foreign keys and indexes
A very common misunderstanding is that indexes are automatically created for foreign keys. While most of the times you need them they are NOT automatically created by SQL Server and before you ask... SQL Server NEVER created them automatically. When your database grows in size this may become a very big performance hit.
Your first task is to detect the foreign keys that have missing indexes. I've created the following query for SQL Server 2005. I have to test it some more to be sure it covers everything but on my little test database it seems to work fine. This is obviously a starting point and you can extend the query quite easily. I'm not checking if the index is too wide to be considered yet, but obviously none of you guys have such wide indexes right?
I'll give it a try on a bigger database tomorrow since it's getting kind of late now ;-)
SELECT fk.Name as 'ForeignKey', OBJECT_NAME(fk.parent_object_id) as 'ChildTable',
OBJECT_NAME(fk.referenced_object_id) as 'ParentTable', c.Name as 'Column', i.Name as 'ValidIndex'
FROM sys.foreign_keys fk
INNER JOIN sys.foreign_key_columns fkc ON fk.object_id = fkc.constraint_object_id
INNER JOIN sys.columns c ON c.object_id = fk.parent_object_id AND c.column_id = fkc.parent_column_id
LEFT OUTER JOIN sys.index_columns ic ON ic.object_id = fk.parent_object_id AND c.column_id = ic.column_id AND ic.index_column_id = 1
LEFT OUTER JOIN sys.indexes i ON i.object_id = ic.object_id AND i.index_id = ic.index_id
ORDER BY ChildTable, ParentTable
Your first task is to detect the foreign keys that have missing indexes. I've created the following query for SQL Server 2005. I have to test it some more to be sure it covers everything but on my little test database it seems to work fine. This is obviously a starting point and you can extend the query quite easily. I'm not checking if the index is too wide to be considered yet, but obviously none of you guys have such wide indexes right?
I'll give it a try on a bigger database tomorrow since it's getting kind of late now ;-)
SELECT fk.Name as 'ForeignKey', OBJECT_NAME(fk.parent_object_id) as 'ChildTable',
OBJECT_NAME(fk.referenced_object_id) as 'ParentTable', c.Name as 'Column', i.Name as 'ValidIndex'
FROM sys.foreign_keys fk
INNER JOIN sys.foreign_key_columns fkc ON fk.object_id = fkc.constraint_object_id
INNER JOIN sys.columns c ON c.object_id = fk.parent_object_id AND c.column_id = fkc.parent_column_id
LEFT OUTER JOIN sys.index_columns ic ON ic.object_id = fk.parent_object_id AND c.column_id = ic.column_id AND ic.index_column_id = 1
LEFT OUTER JOIN sys.indexes i ON i.object_id = ic.object_id AND i.index_id = ic.index_id
ORDER BY ChildTable, ParentTable
Monday, March 13, 2006
DevDays 2006 - Clarification
I noticed on Tom Mertens' blog that my words may have been a little too harsh so I felt I should give a more nuanced response. I do not mean any disrespect and I know everyone works very hard to organize such an event. I was just expressing my own personal feeling at that time.I took the SQL Server track and maybe my comment on Tom's blog explains why I personally didn't like it too much. It could be the difference between IT Pro's and Developers which I am... a Database Developer :-)
Maybe this is the real problem in Belgium, Database Developers are kind of an unknown species and we don't see many projects that actually have people that do just that. I hope more and more companies will start to understand the importance of Database Developers so the DevDays can have a separate Database Developers track :-D
Maybe this is the real problem in Belgium, Database Developers are kind of an unknown species and we don't see many projects that actually have people that do just that. I hope more and more companies will start to understand the importance of Database Developers so the DevDays can have a separate Database Developers track :-D
Sunday, March 12, 2006
4GB of VAS under WOW, does it really worth it?
Another great post by the SQL Server Memory Guru: here
Also check out this suggestion coming from Greg Low (MVP). Although it is a feature in Oracle I still think it is a great idea :-) Being able to define your variable type as the column type gets rid of the sometimes painful type mismatches between parameters/variables and column data types. Having the wrong datatype can cause very odd behavior from the Query Optimizer. It also saves you a lot of work when you change the datatype of a specific column. Go VOTE :-D
From the suggestion: DECLARE @TradingName dbo.Customers.TradingName
Also check out this suggestion coming from Greg Low (MVP). Although it is a feature in Oracle I still think it is a great idea :-) Being able to define your variable type as the column type gets rid of the sometimes painful type mismatches between parameters/variables and column data types. Having the wrong datatype can cause very odd behavior from the Query Optimizer. It also saves you a lot of work when you change the datatype of a specific column. Go VOTE :-D
From the suggestion: DECLARE @TradingName dbo.Customers.TradingName
Wednesday, March 08, 2006
DevDays 2006
So... I just attended the Belgian edition of the DevDays.
To be honest I wasn't too thrilled about the sessions, most of the content was too high level to be interesting. I think the technologies presented are already 'too old' to talk about them in such a way. Most of us freaky developers read too much about it or even worked too much with them already.
I was impressed by the visual effects in Vista though. It looks like something in a science fiction movie and I got the urge to grab the windows in a virtual reality kind of way :-) The upgrade-your-memory-by-using-a-usb-stick was really 'funky' too. Apart from that the deployment options seem quite impressive. Unfortunately I took the SQL track for the rest of the day so I didn't get a chance to see some more new features.
Another interesting thing is the creation of the Belgian SQL Server User Group (http://www.bemssug.org/). Finally some Belgian activity in the SQL Server world; the development side of SQL Server is often forgotten in Belgium so I hope these guys will have some interest in that side of the SQL Server story too.
To be honest I wasn't too thrilled about the sessions, most of the content was too high level to be interesting. I think the technologies presented are already 'too old' to talk about them in such a way. Most of us freaky developers read too much about it or even worked too much with them already.
I was impressed by the visual effects in Vista though. It looks like something in a science fiction movie and I got the urge to grab the windows in a virtual reality kind of way :-) The upgrade-your-memory-by-using-a-usb-stick was really 'funky' too. Apart from that the deployment options seem quite impressive. Unfortunately I took the SQL track for the rest of the day so I didn't get a chance to see some more new features.
Another interesting thing is the creation of the Belgian SQL Server User Group (http://www.bemssug.org/). Finally some Belgian activity in the SQL Server world; the development side of SQL Server is often forgotten in Belgium so I hope these guys will have some interest in that side of the SQL Server story too.
Wednesday, March 01, 2006
GRANT EXECUTE
A lot of SQL Server projects are using stored procedures to control their query behavior (which I like because developers shouldn't be in control of this :p). In previous versions of SQL Server there was something that was kind of disturbing in terms of security. In order to grant execute permissions to a user you had to give permission to every single stored procedure the user needed. When you have 1000 stored procedures you wouldn't want to do this manually so there was the possibility to generate a script by using sysobjects or INFORMATION_SCHEMA.Routines but you need to keep the permissions up-to-date when new procedures were created.
SQL Server 2005 has a great solution to this: GRANT EXECUTE
You can now create a database user role that has execute permissions on all the objects in that database.
CREATE ROLE db_ICanExecute
GO
GRANT EXECUTE TO db_ICanExecute
GO
SQL Server 2005 has a great solution to this: GRANT EXECUTE
You can now create a database user role that has execute permissions on all the objects in that database.
CREATE ROLE db_ICanExecute
GO
GRANT EXECUTE TO db_ICanExecute
GO
Monday, February 27, 2006
Fun with jobs and the public role and proxies
My colleague came across some interesting 'features' with SSIS in jobs.
This results in the following error message: "Msg 14523, Level 16,
State 1, Procedure sp_revoke_login_from_proxy, Line 63 "public" has not been granted permission to use proxy "myProxy"."
Also notice the @enabled parameter in the sp_add_proxy call. We can't find this in the interface but when this parameter is set to 0 the proxy is disabled. The problem is that you CAN select
disabled proxies as the account to run the job with but the job fails on execution.
- When you execute a job and change the data sources the information is NOT stored and the next execution resets the connection information. Using a config file is definitely the way to go :-)
- Proxy accounts with the public role assigned to it have a problem removing this role.
USE [master]
GO
CREATE CREDENTIAL [myCredentials] WITH IDENTITY = N'svcaccount',
SECRET = N'xxxxxxxxx'
GO
USE [msdb]
GO
EXEC msdb.dbo.sp_add_proxy @proxy_name=N'myProxy',
@credential_name=N'myCredentials', @enabled=1
GO
EXEC msdb.dbo.sp_grant_proxy_to_subsystem @proxy_name=N'myProxy',
@subsystem_id=11
GO
EXEC msdb.dbo.sp_grant_login_to_proxy @proxy_name=N'myProxy',
@msdb_role=N'public'
GO
USE [msdb]
GO
EXEC msdb.dbo.sp_revoke_login_from_proxy @proxy_name=N'myProxy',
@name=N'public'
GO
This results in the following error message: "Msg 14523, Level 16,
State 1, Procedure sp_revoke_login_from_proxy, Line 63 "public" has not been granted permission to use proxy "myProxy"."
Also notice the @enabled parameter in the sp_add_proxy call. We can't find this in the interface but when this parameter is set to 0 the proxy is disabled. The problem is that you CAN select
disabled proxies as the account to run the job with but the job fails on execution.
Wednesday, February 22, 2006
Improving Data Security by Using SQL Server 2005
It's kind of old but I just stumbled upon this whitepaper about the encryption functionality in SQL Server 2005
Enjoy!
Enjoy!
Tuesday, February 21, 2006
SQL Server 2005 Upgrade Advisor
If you are planning to migrate your SQL Server to SQL Server 2005 please make sure you run the SQL Server 2005 Upgrade Advisor. This free tool provided by Microsoft checks your current installation and detects the possible problems that will occur when you upgrade. The Upgrade Advisor also checks for some Best Practices on SQL Server and it's services.
It is able to check the following:
- SQL Server
- Analysis Services
- Notification Services
- Reporting Services
- Data Transformation Services
Do note that in order to check Reporting Services the Upgrade Advisor needs to be installed on the Report Server, the other services can be checked remotely.
You can choose to check your database(s), a trace file or a SQL batch. When the analysis has been completed a very clear report is created stating the current problems. These are expandable and contain more detailed information. Most of the details contain a link with even more detail on the problem and more important... how to fix it! When applicable the list of objects that are affected by this problem is available too.
This is really a great tool and I would advise you to ALWAYS run it if you are planning to upgrade a database. There are also other tools available when you want to migrate from Oracle. I think other database migration tools will be available too in the future.
Friday, February 17, 2006
SQL Server vs SAN
Recently we have been looking at some performance problems on some of our servers. I found some interesting information concerning SAN's so here is a little high level overview of things to remember.
- Format the Data drives with 64k sector size, the Log drive with at least 8k.
- Align the disks using diskpar in Windows 2003 (diskpart for SP1+) or do this at SAN level if possible (10%-20% improvement in some studies).
- Use StorPort drivers for your HBA's. SCSIPort was designed for direct attached storage while StorPort is optimized for SAN I/O) - Info
- Choose RAID 10 over RAID5. Although certain SAN's have optimized RAID5 technology that reduce the overhead RAID10 is still the preferred level.
- Spread over as many disks as possible.
- Always separate your data from your log drives. Log is sequential while data is more random I/O, mixing these might cause log latency.
- Stress test your SAN with realistic file sizes.
Tuesday, February 14, 2006
Clustered indexes on GUIDs
Hmm... this is actually a debate that will go on forever I suppose :-) I've created a little test script to prove a specific point but do NOT think of this as a complete negative advise for clustered indexes on GUIDs. Every DBA should know the sentence 'it all depends' by heart and actually you should *sigh* when someone asks: "What is the best solution for the database?" without knowing the data, the usage of the data and the environment it will run in.
What I wanted to test was fragmentation because of random uniqueidentifiers. When you run this script you will see amazing high figures for the fragmentation factor after just 1000 inserts! On my machine this small set of inserts generated 96,84% fragmentation and 587 fragments.
SQL Server 2005 has a new feature that may ease your fragmentation pain and that is sequential GUIDs. This generates uniqueidentifiers but based on the previous uniqueidentifier. This is great if you still want to use GUIDs but want to get rid of it's biggest strength and drawback which is it's random nature. When you change the script to use sequential GUIDs the fragmentation drops to 0.95% and 6 fragments. This is a quite spectacular drop. However, it is not always possible to use this because I know a lot of you are generating GUIDs on the clientside or middle tier making this unavailable since a sequential GUID can only be used as a default.
Fragmentation does have a lot of negative impact such as reduced scan speed and more pages are needed in memory because the data is spread over a lot of different pages. Is this ALWAYS a bad thing? Well there is something called a hotspot meaning all actions are concentrated on a single 'spot'. This may reduce performance but has been greatly reduced by the introduction of row locking. How many inserts are needed to create a hotspot? Well... it all depends :-) You can use the link from my previous post where a nice script has been provided to detect hotspots and lock contention using the new DMV's.
What I wanted to test was fragmentation because of random uniqueidentifiers. When you run this script you will see amazing high figures for the fragmentation factor after just 1000 inserts! On my machine this small set of inserts generated 96,84% fragmentation and 587 fragments.
SQL Server 2005 has a new feature that may ease your fragmentation pain and that is sequential GUIDs. This generates uniqueidentifiers but based on the previous uniqueidentifier. This is great if you still want to use GUIDs but want to get rid of it's biggest strength and drawback which is it's random nature. When you change the script to use sequential GUIDs the fragmentation drops to 0.95% and 6 fragments. This is a quite spectacular drop. However, it is not always possible to use this because I know a lot of you are generating GUIDs on the clientside or middle tier making this unavailable since a sequential GUID can only be used as a default.
Fragmentation does have a lot of negative impact such as reduced scan speed and more pages are needed in memory because the data is spread over a lot of different pages. Is this ALWAYS a bad thing? Well there is something called a hotspot meaning all actions are concentrated on a single 'spot'. This may reduce performance but has been greatly reduced by the introduction of row locking. How many inserts are needed to create a hotspot? Well... it all depends :-) You can use the link from my previous post where a nice script has been provided to detect hotspots and lock contention using the new DMV's.
SET NOCOUNT ON
GO
CREATE TABLE myFragmentation
(myID uniqueidentifier)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 100000
BEGIN
INSERT INTO myFragmentation (myID) VALUES (NewID())
SET @i = @i + 1
END
GO
SELECT * FROM
sys.dm_db_index_physical_stats
(DB_ID(), OBJECT_ID('myFragmentation'), NULL, NULL, 'DETAILED')
GO
CREATE UNIQUE CLUSTERED INDEX myCI ON myFragmentation (myID)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 1000
BEGIN
INSERT INTO myFragmentation (myID) VALUES (NewID())
SET @i = @i + 1
END
SELECT * FROM
sys.dm_db_index_physical_stats
(DB_ID(), OBJECT_ID('myFragmentation'), 1, NULL, 'DETAILED')
DROP TABLE myFragmentation
Index information using DMV's
Wow, this is a GREAT post by the Customer Advisory Team.
http://blogs.msdn.com/sqlcat/archive/2006/02/13/531339.aspx
http://blogs.msdn.com/sqlcat/archive/2006/02/13/531339.aspx
Sunday, February 12, 2006
SSIS Variables in Execute SQL Task
When trying to use an input variable in my Execute SQL Task I was getting the following error:"Parameter name is unrecognized." and the package obviously failed.
After some playing around I noticed that it had something to do with the difference in variable mapping declaration based on your connection type.
Based on your connection type you have to choose the correct name in your Parameter Mapping window.
Here is a little overview (credits go to Kirk Haselden):
OLEDB takes ? in the query and a number as name (0, 1, ...)
ODBC takes ? in the query and a number as name (1, 2, ...)
ADO takes ? in the query and a @Variable as name
ADO.Net takes @Variable in both the query and the name
Also make sure to choose the correct datatype for the parameter!
After some playing around I noticed that it had something to do with the difference in variable mapping declaration based on your connection type.
Based on your connection type you have to choose the correct name in your Parameter Mapping window.
Here is a little overview (credits go to Kirk Haselden):
OLEDB takes ? in the query and a number as name (0, 1, ...)
ODBC takes ? in the query and a number as name (1, 2, ...)
ADO takes ? in the query and a @Variable as name
ADO.Net takes @Variable in both the query and the name
Also make sure to choose the correct datatype for the parameter!
Tuesday, February 07, 2006
Transaction Log behavior
Recently I've been asked to investigate the migration possibilities of our Reporting Services environment to SQL Server 2005. Up until now everything has been really smooth to migrate and no real issues have come out of the process.
Yesterday I noticed that our BULK INSERT tasks were taking a lot longer as opposed to the SQL Server 2000 runtime. I am testing this on the same server with the exact same import files and database settings so there has to be a reason why it is taking twice as long as before. Off to investigate!
While checking all possible bottlenecks I came across a big difference and this was the Transaction Log size. While it is sized at 2GB and remains that size on the 2000 instance (Simple Recovery) it grows to 12GB on the 2005 instance.
Adding an explicit TABLOCK to the BULK INSERT statement seems to help. I admit we should have included this in the first place :-) Minimally logged operations do have some prerequisites and this is one of them. Others are that the table is not being replicated, simple or bulk logged recovery model and there are some index restrictions you can check in the books online.
However, this does not explain the difference between the two versions as those rules apply to both versions.
More to follow!
Yesterday I noticed that our BULK INSERT tasks were taking a lot longer as opposed to the SQL Server 2000 runtime. I am testing this on the same server with the exact same import files and database settings so there has to be a reason why it is taking twice as long as before. Off to investigate!
While checking all possible bottlenecks I came across a big difference and this was the Transaction Log size. While it is sized at 2GB and remains that size on the 2000 instance (Simple Recovery) it grows to 12GB on the 2005 instance.
Adding an explicit TABLOCK to the BULK INSERT statement seems to help. I admit we should have included this in the first place :-) Minimally logged operations do have some prerequisites and this is one of them. Others are that the table is not being replicated, simple or bulk logged recovery model and there are some index restrictions you can check in the books online.
However, this does not explain the difference between the two versions as those rules apply to both versions.
More to follow!
Monday, February 06, 2006
Non-unique clustered index rebuild in SQL Server 2005
One of the big disadvantages of SQL Server 2000 non-unique clustered indexes was the fact that SQL Server generated a new uniqueifier whenever you would rebuild your index. Although the general guideline remains to create narrow, unique and ever-increasing clustered indexes SQL Server 2005 has a nice improvement over SQL Server 2000.
SQL Server 2005 no longer changes the uniqueifier when you rebuild it which is great news! You now have more control over when you want to rebuild your non-clustered indexes if your table has a non-unique clustered index. This is true for ALTER INDEX, DBCC DBREINDEX as well as CREATE INDEX WITH DROP_EXISTING.
Here is a little script to show this behavior.
I check the STATS_DATE because whenever your indexes are being rebuilt your statistics will be updated with a fullscan.
SQL Server 2005 no longer changes the uniqueifier when you rebuild it which is great news! You now have more control over when you want to rebuild your non-clustered indexes if your table has a non-unique clustered index. This is true for ALTER INDEX, DBCC DBREINDEX as well as CREATE INDEX WITH DROP_EXISTING.
Here is a little script to show this behavior.
I check the STATS_DATE because whenever your indexes are being rebuilt your statistics will be updated with a fullscan.
CREATE
TABLE myUniqueifierTest(
myID int,myChar char(200)
)
GO
INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('X', 200))INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('Y', 200))INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('Z', 200))GO
CREATE
CLUSTERED INDEX myCI ON myUniqueifierTest (myID)GO
CREATE
NONCLUSTERED INDEX myNCI ON myUniqueifierTest (myChar)GO
WAITFOR
DELAY '00:00:03'ALTER
INDEX myCI ON myUniqueifierTestREBUILD
GO
--DBCC DBREINDEX(myUniqueifierTest, myCI)
--CREATE CLUSTERED INDEX myCI ON myUniqueifierTest (myID) WITH DROP_EXISTING
SELECT
STATS_DATE ( OBJECT_ID('myUniqueifierTest'), 1 )SELECT
STATS_DATE ( OBJECT_ID('myUniqueifierTest'), 2 )GO
DROP
TABLE myUniqueifierTestFriday, February 03, 2006
SSWUG Radio
Chuck Boyce (http://chuckboyce.blogspot.com/) has a daily session called "The Where Clause". He makes an overview of the interesting blog posts of the day and yesterday he mentioned mine :-)
Check it out: http://www.sswug.org/sswugradio/the_where_clause_02feb2006.mp3
Thanks Chuck.
Check it out: http://www.sswug.org/sswugradio/the_where_clause_02feb2006.mp3
Thanks Chuck.
Wednesday, February 01, 2006
Equijoin and search predicates in SQL Server 2005
In older versions of SQL Server a common optimization technique for equijoins with a criteria on one of the fields of the equijoin was to add the criteria for both tables.
eg.
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3 AND p.myID > 3
Because we are talking about an equijoin one can conclude that the myID field should be > 3 for both tables if it was requested for one of the tables.
SQL Server 2005 however is a bit smarter than older versions and comes up with a correct query plan all by itself.
When executing the following query in SQL Server 2005 you will see in the query plan that SQL Server takes into account the equijoin with the correct criteria for both tables:
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3
eg.
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3 AND p.myID > 3
Because we are talking about an equijoin one can conclude that the myID field should be > 3 for both tables if it was requested for one of the tables.
SQL Server 2005 however is a bit smarter than older versions and comes up with a correct query plan all by itself.
When executing the following query in SQL Server 2005 you will see in the query plan that SQL Server takes into account the equijoin with the correct criteria for both tables:
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3

Notice how the the Seek Predicates for tblParent contains myID > 3 too.
Another little optimization that makes your life a little easier. The best part is that optimizations like this are for free, meaning no changes have to be made to your existing queries to benefit from this. There are a couple more optimizations like these, for example: statement level recompilation for stored procedures, caching of plans that use dynamic objects (like table variables), various tempdb optimizations, ...
As a side note do remember that the recommendations for tempdb in SQL Server 2000 are still valid for SQL Server 2005. For those of you that don't know them or have forgotten them:
- Avoid autogrowth
- Use as many files as there are CPU's (take into account the processor affinity setting)
- Equally size the files
Thursday, January 26, 2006
Slow mass deletes
My favorite Lead DBA Patrick asked me to find out how we could delete millions of rows from a table in the fastest way possible. You guessed it... this too is linked to the archiving project :-)
I was inspired by a blogpost from Kimberly Tripp where she tested mass deletes extensively with all different kinds of indexing.
The conclusion was that deletes from tables with non-clustered indexes was a lot slower as opposed to tables with only a clustered index.
When I started testing the delete options I suddenly noticed that there was a lot of locking activity on TempDB. Freaky as I can get I needed to find out why this was happening.
So off to investigate!
I've created a small table with the following script:
Check the active locks with sp_lock and there you go... lots and lots of extent locks on TempDB.
Now why is this happening?
It is actually very simple to find out... the query plan says it all!
After the Clustered Index Delete you will see a Table Spool/Eager Spool action for every non-clustered index. The description of this action is quite clear: "Stores the data from the input in a temporary table in order to optimize rewinds". This is followed by a Sort, an Index Delete, a Sequence and finally the delete is final.
You can imagine that these spools, sorts, ... can be quite intrusive when we are talking about 40 to 100 million rows.
Another mystery solved!
I was inspired by a blogpost from Kimberly Tripp where she tested mass deletes extensively with all different kinds of indexing.
The conclusion was that deletes from tables with non-clustered indexes was a lot slower as opposed to tables with only a clustered index.
When I started testing the delete options I suddenly noticed that there was a lot of locking activity on TempDB. Freaky as I can get I needed to find out why this was happening.
So off to investigate!
I've created a small table with the following script:
Let's delete everything from this table:
SET NOCOUNT ON
GO
CREATE TABLE TestNCDelete
(myID int IDENTITY(1,1),
myChar char(500),
myVarChar varchar(500)
)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 10000
BEGIN
INSERT INTO TestNCDelete (myChar, myVarChar)
VALUES (' ', REPLICATE('A', 500))
SET @i = @i + 1
END
CREATE UNIQUE CLUSTERED INDEX CI_myID ON TestNCDelete (myID)
GO
CREATE INDEX IX_myChar ON TestNCDelete (myChar)
GO
CREATE INDEX IX_myVarChar ON TestNCDelete (myVarChar)
GO
--DROP TABLE TestNCDelete
BEGIN TRAN
DELETE FROM TestNCDelete WITH (TABLOCKX)
--ROLLBACK
Check the active locks with sp_lock and there you go... lots and lots of extent locks on TempDB.
Now why is this happening?
It is actually very simple to find out... the query plan says it all!
After the Clustered Index Delete you will see a Table Spool/Eager Spool action for every non-clustered index. The description of this action is quite clear: "Stores the data from the input in a temporary table in order to optimize rewinds". This is followed by a Sort, an Index Delete, a Sequence and finally the delete is final.
You can imagine that these spools, sorts, ... can be quite intrusive when we are talking about 40 to 100 million rows.
Another mystery solved!
Tuesday, January 24, 2006
Fun with RAW Destination files
As I said before one of the hot projects is Archiving. Because it is the first time a functional archiving process will take place we are talking about a lot of data and a small maintenance window. All this makes performance a key factor.
How do you achieve high performance with SSIS exports?
Use the Raw File Destination.
We have tested a couple of parallel exports to Flat File and repeated this action to the Raw File Destination. The export process went from 31 minutes to 26 minutes and the file size decreased to an incredible 2/3 of the size the Flat File Destination took. Now this may not look like a big gain but all this was as easy as changing the destination type. Another problem is that we are reaching our max read performance. I am convinced that there are more tuning options available and will probably be exploring these tomorrow.
The import process is blazing fast but I will be tuning this even more tomorrow too... let's see what we learn from that. Stay tuned!
How do you achieve high performance with SSIS exports?
Use the Raw File Destination.
We have tested a couple of parallel exports to Flat File and repeated this action to the Raw File Destination. The export process went from 31 minutes to 26 minutes and the file size decreased to an incredible 2/3 of the size the Flat File Destination took. Now this may not look like a big gain but all this was as easy as changing the destination type. Another problem is that we are reaching our max read performance. I am convinced that there are more tuning options available and will probably be exploring these tomorrow.
The import process is blazing fast but I will be tuning this even more tomorrow too... let's see what we learn from that. Stay tuned!
Monday, January 23, 2006
Fun with Lookups in SSIS
One of the current hot projects here is archiving (the database grows with +1GB/day). For one of the solutions we need two files from the same table based on a staging table. This is now done in 2 steps so I tried to figure out a way to read the table only once.
I noticed that the Lookup Transformation has an option to redirect a row when an error occurs. This enables us to separate the output to 2 separate files based on the lookup table.
I started testing and I was thrilled by the performance of these transformations. So off to do the 'real' work, a lookup table with 40.000.000 records (holding just a guid) to export a table with 120.000.000 records. Unfortunately I hit the first 32-bit limitation :-( Because of the massive amount of data SSIS is having trouble reading all the records in memory. I get up to about 38.000.000 rows and then the process stalls. After quite some time I get the following error:
0xC0047031 DTS_E_THREADFAILEDCREATE
The Data Flow task failed to create a required thread and cannot begin running. The usually occurs when there is an out-of-memory state.
SSIS cannot use AWE memory so it depends entirely on the VAS memory meaning only 2GB (or 3 with /3GB enabled) on a 32-bit environment. If we were running a 64-bit environment all my worries would be over :-(
I could skip the cache or cache less data but then it becomes quite slow and the 'double' export runs better in that case.
Who knows... maybe tomorrow I will find a solution.
I noticed that the Lookup Transformation has an option to redirect a row when an error occurs. This enables us to separate the output to 2 separate files based on the lookup table.
I started testing and I was thrilled by the performance of these transformations. So off to do the 'real' work, a lookup table with 40.000.000 records (holding just a guid) to export a table with 120.000.000 records. Unfortunately I hit the first 32-bit limitation :-( Because of the massive amount of data SSIS is having trouble reading all the records in memory. I get up to about 38.000.000 rows and then the process stalls. After quite some time I get the following error:
0xC0047031 DTS_E_THREADFAILEDCREATE
The Data Flow task failed to create a required thread and cannot begin running. The usually occurs when there is an out-of-memory state.
SSIS cannot use AWE memory so it depends entirely on the VAS memory meaning only 2GB (or 3 with /3GB enabled) on a 32-bit environment. If we were running a 64-bit environment all my worries would be over :-(
I could skip the cache or cache less data but then it becomes quite slow and the 'double' export runs better in that case.
Who knows... maybe tomorrow I will find a solution.
Friday, January 20, 2006
Myth Busters
Euan started a nice category on his blog... Myth Busters (love that show btw).
Instead of trying to sink a boat with a self constructed shark Euan will try to explain some SQL Server Myths (and probably bust a couple - 1 down... many to go)
Here
Instead of trying to sink a boat with a self constructed shark Euan will try to explain some SQL Server Myths (and probably bust a couple - 1 down... many to go)
Here
Thursday, January 19, 2006
SSIS Performance Tips
Not that I am an experienced SSIS developer but I'll try to give some general guidelines to optimize the performance of bulk import operations.
- Try to get your flat files sorted by the clustered index of the destination table
- Use the 'Fast Parse' option; there are some limitations for date (time) and integer data
- For OLEDB Connections use the Fast Load setting
- Use a SQL Server Destination if possible (can be up to 25% faster!)
- Use BULK_LOGGED recovery model for your SQL Server destinations
- The MaxConcurrentExecutables package setting defines how many tasks can run concurrently (default number of logical cpus + 2)
- Change the EngineThreads property of a task (defaults to 5 but could support more on multi-processor servers - testing is the key)
- Run parallel import steps if possible
- Use the right isolation level for your package and container
- Import into a heap from multiple files in parallel and then recreate the indexes (clustered first then the non-clustered indexes)
Long term memory
Today I convinced a colleague to start blogging by telling him that I consider it my long-term memory.
He is the tool guru aka Mr. Concept (and a bit .NET guru too :p)
http://www.bloglines.com/blog/General1
He is the tool guru aka Mr. Concept (and a bit .NET guru too :p)
http://www.bloglines.com/blog/General1
Monday, January 16, 2006
Treeview AfterSelect and changing focus
When you want to set focus to another control in the AfterSelect method of a treeview there seems to be a problem with the behavior. Focus is set to the control but is then returned to the Treeview.
Forcing the Focus asynchronously seems to solve this little issue.
How?
Add a delegate:
private delegate bool _methodInvoker();
Now in the AfterSelect handler add the following code:
myControl.BeginInvoke(new _methodInvoker(myControl.Focus));
Kept me busy quite some time :-(
Forcing the Focus asynchronously seems to solve this little issue.
How?
Add a delegate:
private delegate bool _methodInvoker();
Now in the AfterSelect handler add the following code:
myControl.BeginInvoke(new _methodInvoker(myControl.Focus));
Kept me busy quite some time :-(
Thursday, January 12, 2006
Missing Indexes Feature
Especially for my favorite colleague Tom :-)
SQL Server hold information about missing indexes in a couple of dmv's.
sys.dm_db_missing_index_group_stats: holds information about the possible performance improvement when implementing a group of indexes
sys.dm_db_missing_index_groups: holds information about possible groups of indexes
sys.dm_db_missing_index_details: holds details about the missing indexes
sys.dm_db_missing_index_columns: holds the list of columns that could use indexes
This is a great feature but as always it has some limitations.
From the BOL:
Remember that it is not the holy grail but yet again a nice addition that guides you in the right direction. Performance remains the responsibility of the DBA that has to make the right decision for the specific workload and configuration available. Proper modeling and indexing remains a key factor in high performance applications that squeeze out the last drop of hardware-power.
SQL Server hold information about missing indexes in a couple of dmv's.
sys.dm_db_missing_index_group_stats: holds information about the possible performance improvement when implementing a group of indexes
sys.dm_db_missing_index_groups: holds information about possible groups of indexes
sys.dm_db_missing_index_details: holds details about the missing indexes
sys.dm_db_missing_index_columns: holds the list of columns that could use indexes
This is a great feature but as always it has some limitations.
From the BOL:
- It is not intended to fine tune an indexing configuration.
- It cannot gather statistics for more than 500 missing index groups.
- It does not specify an order for columns to be used in an index.
- For queries involving only inequality predicates, it returns less accurate cost information.
- It reports only include columns for some queries, so index key columns must
be manually selected.- It returns only raw information about columns on which
indexes might be missing.- It can return different costs for the same missing
index group that appears multiple times in XML Showplans.
Remember that it is not the holy grail but yet again a nice addition that guides you in the right direction. Performance remains the responsibility of the DBA that has to make the right decision for the specific workload and configuration available. Proper modeling and indexing remains a key factor in high performance applications that squeeze out the last drop of hardware-power.
Tuesday, January 10, 2006
Microsoft Minded?
I guess I'm pretty Microsoft minded and with good reason so far.
But some people really go well beyond being 'MS minded' :)
Here
But some people really go well beyond being 'MS minded' :)
Here
Friday, January 06, 2006
Integration Services vs Named Instances
If you are encountering 'Login Timeout' messages when trying to connect to the MSDB database of your Integration Services check if you have installed it on a server with only named instance.
Integration Services points to the default instance of the localhost. If you don't have a default instance you need to change the MsDtsSrvr.ini.xml file in \Program Files\Microsoft SQL Server\90\DTS\Binn. Find the ServerNameconfiguration and change it to point to one of your named instances.
Integration Services points to the default instance of the localhost. If you don't have a default instance you need to change the MsDtsSrvr.ini.xml file in \Program Files\Microsoft SQL Server\90\DTS\Binn. Find the ServerName
Thursday, January 05, 2006
System.Transaction
I'm probably a few months behind but I recently read that the new Windows Vista will support a filesystem and registry that is capable of transactions in combination with the new System.Transaction assembly.
Now that's a very nice feature!
Now that's a very nice feature!
Wednesday, January 04, 2006
An unexpected error occurred in Report Processing. (rsUnexpectedError) - Hotfix
Finally some information about this.
We have confirmation from Microsoft that it is indeed a bug in ALL versions of Reporting Services. A hotfix request will be sent by us to solve this problem.
We have confirmation from Microsoft that it is indeed a bug in ALL versions of Reporting Services. A hotfix request will be sent by us to solve this problem.
Nifty features in Management Studio
As you know Management Studio has lots of improvements and some are quite technical and usefull. Sometimes I stumble upon some little 'improvements' that are more or less cute.
When adding a clustered index to a table with non-clustered indexes I received the following message box.
Cute huh :-)
When adding a clustered index to a table with non-clustered indexes I received the following message box.

Cute huh :-)
Tuesday, January 03, 2006
.NET 2.0
Finally found some time this weekend to play around with .NET 2.0.
Although I haven't seen a lot I'm already quite pleased with Master Pages and Themes. There are some nice improvements to the tools too like a tool to manage your web.config, refactoring in Visual Studio, ...
Next on the list:
MARS
Explore the possibilities of the GridView control
Although I haven't seen a lot I'm already quite pleased with Master Pages and Themes. There are some nice improvements to the tools too like a tool to manage your web.config, refactoring in Visual Studio, ...
Next on the list:
MARS
Explore the possibilities of the GridView control
Subscribe to:
Posts (Atom)
