When trying to use an input variable in my Execute SQL Task I was getting the following error:"Parameter name is unrecognized." and the package obviously failed.
After some playing around I noticed that it had something to do with the difference in variable mapping declaration based on your connection type.
Based on your connection type you have to choose the correct name in your Parameter Mapping window.
Here is a little overview (credits go to Kirk Haselden):
OLEDB takes ? in the query and a number as name (0, 1, ...)
ODBC takes ? in the query and a number as name (1, 2, ...)
ADO takes ? in the query and a @Variable as name
ADO.Net takes @Variable in both the query and the name
Also make sure to choose the correct datatype for the parameter!
Sunday, February 12, 2006
Tuesday, February 07, 2006
Transaction Log behavior
Recently I've been asked to investigate the migration possibilities of our Reporting Services environment to SQL Server 2005. Up until now everything has been really smooth to migrate and no real issues have come out of the process.
Yesterday I noticed that our BULK INSERT tasks were taking a lot longer as opposed to the SQL Server 2000 runtime. I am testing this on the same server with the exact same import files and database settings so there has to be a reason why it is taking twice as long as before. Off to investigate!
While checking all possible bottlenecks I came across a big difference and this was the Transaction Log size. While it is sized at 2GB and remains that size on the 2000 instance (Simple Recovery) it grows to 12GB on the 2005 instance.
Adding an explicit TABLOCK to the BULK INSERT statement seems to help. I admit we should have included this in the first place :-) Minimally logged operations do have some prerequisites and this is one of them. Others are that the table is not being replicated, simple or bulk logged recovery model and there are some index restrictions you can check in the books online.
However, this does not explain the difference between the two versions as those rules apply to both versions.
More to follow!
Yesterday I noticed that our BULK INSERT tasks were taking a lot longer as opposed to the SQL Server 2000 runtime. I am testing this on the same server with the exact same import files and database settings so there has to be a reason why it is taking twice as long as before. Off to investigate!
While checking all possible bottlenecks I came across a big difference and this was the Transaction Log size. While it is sized at 2GB and remains that size on the 2000 instance (Simple Recovery) it grows to 12GB on the 2005 instance.
Adding an explicit TABLOCK to the BULK INSERT statement seems to help. I admit we should have included this in the first place :-) Minimally logged operations do have some prerequisites and this is one of them. Others are that the table is not being replicated, simple or bulk logged recovery model and there are some index restrictions you can check in the books online.
However, this does not explain the difference between the two versions as those rules apply to both versions.
More to follow!
Monday, February 06, 2006
Non-unique clustered index rebuild in SQL Server 2005
One of the big disadvantages of SQL Server 2000 non-unique clustered indexes was the fact that SQL Server generated a new uniqueifier whenever you would rebuild your index. Although the general guideline remains to create narrow, unique and ever-increasing clustered indexes SQL Server 2005 has a nice improvement over SQL Server 2000.
SQL Server 2005 no longer changes the uniqueifier when you rebuild it which is great news! You now have more control over when you want to rebuild your non-clustered indexes if your table has a non-unique clustered index. This is true for ALTER INDEX, DBCC DBREINDEX as well as CREATE INDEX WITH DROP_EXISTING.
Here is a little script to show this behavior.
I check the STATS_DATE because whenever your indexes are being rebuilt your statistics will be updated with a fullscan.
SQL Server 2005 no longer changes the uniqueifier when you rebuild it which is great news! You now have more control over when you want to rebuild your non-clustered indexes if your table has a non-unique clustered index. This is true for ALTER INDEX, DBCC DBREINDEX as well as CREATE INDEX WITH DROP_EXISTING.
Here is a little script to show this behavior.
I check the STATS_DATE because whenever your indexes are being rebuilt your statistics will be updated with a fullscan.
CREATE
TABLE myUniqueifierTest(
myID int,myChar char(200)
)
GO
INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('X', 200))INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('Y', 200))INSERT
INTO myUniqueifierTest (myID, myChar)VALUES
(1, REPLICATE('Z', 200))GO
CREATE
CLUSTERED INDEX myCI ON myUniqueifierTest (myID)GO
CREATE
NONCLUSTERED INDEX myNCI ON myUniqueifierTest (myChar)GO
WAITFOR
DELAY '00:00:03'ALTER
INDEX myCI ON myUniqueifierTestREBUILD
GO
--DBCC DBREINDEX(myUniqueifierTest, myCI)
--CREATE CLUSTERED INDEX myCI ON myUniqueifierTest (myID) WITH DROP_EXISTING
SELECT
STATS_DATE ( OBJECT_ID('myUniqueifierTest'), 1 )SELECT
STATS_DATE ( OBJECT_ID('myUniqueifierTest'), 2 )GO
DROP
TABLE myUniqueifierTestFriday, February 03, 2006
SSWUG Radio
Chuck Boyce (http://chuckboyce.blogspot.com/) has a daily session called "The Where Clause". He makes an overview of the interesting blog posts of the day and yesterday he mentioned mine :-)
Check it out: http://www.sswug.org/sswugradio/the_where_clause_02feb2006.mp3
Thanks Chuck.
Check it out: http://www.sswug.org/sswugradio/the_where_clause_02feb2006.mp3
Thanks Chuck.
Wednesday, February 01, 2006
Equijoin and search predicates in SQL Server 2005
In older versions of SQL Server a common optimization technique for equijoins with a criteria on one of the fields of the equijoin was to add the criteria for both tables.
eg.
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3 AND p.myID > 3
Because we are talking about an equijoin one can conclude that the myID field should be > 3 for both tables if it was requested for one of the tables.
SQL Server 2005 however is a bit smarter than older versions and comes up with a correct query plan all by itself.
When executing the following query in SQL Server 2005 you will see in the query plan that SQL Server takes into account the equijoin with the correct criteria for both tables:
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3
eg.
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3 AND p.myID > 3
Because we are talking about an equijoin one can conclude that the myID field should be > 3 for both tables if it was requested for one of the tables.
SQL Server 2005 however is a bit smarter than older versions and comes up with a correct query plan all by itself.
When executing the following query in SQL Server 2005 you will see in the query plan that SQL Server takes into account the equijoin with the correct criteria for both tables:
SELECT p.myID FROM tblParent p
JOIN tblChild c ON p.myID = c.myID
WHERE c.myID > 3

Notice how the the Seek Predicates for tblParent contains myID > 3 too.
Another little optimization that makes your life a little easier. The best part is that optimizations like this are for free, meaning no changes have to be made to your existing queries to benefit from this. There are a couple more optimizations like these, for example: statement level recompilation for stored procedures, caching of plans that use dynamic objects (like table variables), various tempdb optimizations, ...
As a side note do remember that the recommendations for tempdb in SQL Server 2000 are still valid for SQL Server 2005. For those of you that don't know them or have forgotten them:
- Avoid autogrowth
- Use as many files as there are CPU's (take into account the processor affinity setting)
- Equally size the files
Thursday, January 26, 2006
Slow mass deletes
My favorite Lead DBA Patrick asked me to find out how we could delete millions of rows from a table in the fastest way possible. You guessed it... this too is linked to the archiving project :-)
I was inspired by a blogpost from Kimberly Tripp where she tested mass deletes extensively with all different kinds of indexing.
The conclusion was that deletes from tables with non-clustered indexes was a lot slower as opposed to tables with only a clustered index.
When I started testing the delete options I suddenly noticed that there was a lot of locking activity on TempDB. Freaky as I can get I needed to find out why this was happening.
So off to investigate!
I've created a small table with the following script:
Check the active locks with sp_lock and there you go... lots and lots of extent locks on TempDB.
Now why is this happening?
It is actually very simple to find out... the query plan says it all!
After the Clustered Index Delete you will see a Table Spool/Eager Spool action for every non-clustered index. The description of this action is quite clear: "Stores the data from the input in a temporary table in order to optimize rewinds". This is followed by a Sort, an Index Delete, a Sequence and finally the delete is final.
You can imagine that these spools, sorts, ... can be quite intrusive when we are talking about 40 to 100 million rows.
Another mystery solved!
I was inspired by a blogpost from Kimberly Tripp where she tested mass deletes extensively with all different kinds of indexing.
The conclusion was that deletes from tables with non-clustered indexes was a lot slower as opposed to tables with only a clustered index.
When I started testing the delete options I suddenly noticed that there was a lot of locking activity on TempDB. Freaky as I can get I needed to find out why this was happening.
So off to investigate!
I've created a small table with the following script:
Let's delete everything from this table:
SET NOCOUNT ON
GO
CREATE TABLE TestNCDelete
(myID int IDENTITY(1,1),
myChar char(500),
myVarChar varchar(500)
)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 10000
BEGIN
INSERT INTO TestNCDelete (myChar, myVarChar)
VALUES (' ', REPLICATE('A', 500))
SET @i = @i + 1
END
CREATE UNIQUE CLUSTERED INDEX CI_myID ON TestNCDelete (myID)
GO
CREATE INDEX IX_myChar ON TestNCDelete (myChar)
GO
CREATE INDEX IX_myVarChar ON TestNCDelete (myVarChar)
GO
--DROP TABLE TestNCDelete
BEGIN TRAN
DELETE FROM TestNCDelete WITH (TABLOCKX)
--ROLLBACK
Check the active locks with sp_lock and there you go... lots and lots of extent locks on TempDB.
Now why is this happening?
It is actually very simple to find out... the query plan says it all!
After the Clustered Index Delete you will see a Table Spool/Eager Spool action for every non-clustered index. The description of this action is quite clear: "Stores the data from the input in a temporary table in order to optimize rewinds". This is followed by a Sort, an Index Delete, a Sequence and finally the delete is final.
You can imagine that these spools, sorts, ... can be quite intrusive when we are talking about 40 to 100 million rows.
Another mystery solved!
Tuesday, January 24, 2006
Fun with RAW Destination files
As I said before one of the hot projects is Archiving. Because it is the first time a functional archiving process will take place we are talking about a lot of data and a small maintenance window. All this makes performance a key factor.
How do you achieve high performance with SSIS exports?
Use the Raw File Destination.
We have tested a couple of parallel exports to Flat File and repeated this action to the Raw File Destination. The export process went from 31 minutes to 26 minutes and the file size decreased to an incredible 2/3 of the size the Flat File Destination took. Now this may not look like a big gain but all this was as easy as changing the destination type. Another problem is that we are reaching our max read performance. I am convinced that there are more tuning options available and will probably be exploring these tomorrow.
The import process is blazing fast but I will be tuning this even more tomorrow too... let's see what we learn from that. Stay tuned!
How do you achieve high performance with SSIS exports?
Use the Raw File Destination.
We have tested a couple of parallel exports to Flat File and repeated this action to the Raw File Destination. The export process went from 31 minutes to 26 minutes and the file size decreased to an incredible 2/3 of the size the Flat File Destination took. Now this may not look like a big gain but all this was as easy as changing the destination type. Another problem is that we are reaching our max read performance. I am convinced that there are more tuning options available and will probably be exploring these tomorrow.
The import process is blazing fast but I will be tuning this even more tomorrow too... let's see what we learn from that. Stay tuned!
Monday, January 23, 2006
Fun with Lookups in SSIS
One of the current hot projects here is archiving (the database grows with +1GB/day). For one of the solutions we need two files from the same table based on a staging table. This is now done in 2 steps so I tried to figure out a way to read the table only once.
I noticed that the Lookup Transformation has an option to redirect a row when an error occurs. This enables us to separate the output to 2 separate files based on the lookup table.
I started testing and I was thrilled by the performance of these transformations. So off to do the 'real' work, a lookup table with 40.000.000 records (holding just a guid) to export a table with 120.000.000 records. Unfortunately I hit the first 32-bit limitation :-( Because of the massive amount of data SSIS is having trouble reading all the records in memory. I get up to about 38.000.000 rows and then the process stalls. After quite some time I get the following error:
0xC0047031 DTS_E_THREADFAILEDCREATE
The Data Flow task failed to create a required thread and cannot begin running. The usually occurs when there is an out-of-memory state.
SSIS cannot use AWE memory so it depends entirely on the VAS memory meaning only 2GB (or 3 with /3GB enabled) on a 32-bit environment. If we were running a 64-bit environment all my worries would be over :-(
I could skip the cache or cache less data but then it becomes quite slow and the 'double' export runs better in that case.
Who knows... maybe tomorrow I will find a solution.
I noticed that the Lookup Transformation has an option to redirect a row when an error occurs. This enables us to separate the output to 2 separate files based on the lookup table.
I started testing and I was thrilled by the performance of these transformations. So off to do the 'real' work, a lookup table with 40.000.000 records (holding just a guid) to export a table with 120.000.000 records. Unfortunately I hit the first 32-bit limitation :-( Because of the massive amount of data SSIS is having trouble reading all the records in memory. I get up to about 38.000.000 rows and then the process stalls. After quite some time I get the following error:
0xC0047031 DTS_E_THREADFAILEDCREATE
The Data Flow task failed to create a required thread and cannot begin running. The usually occurs when there is an out-of-memory state.
SSIS cannot use AWE memory so it depends entirely on the VAS memory meaning only 2GB (or 3 with /3GB enabled) on a 32-bit environment. If we were running a 64-bit environment all my worries would be over :-(
I could skip the cache or cache less data but then it becomes quite slow and the 'double' export runs better in that case.
Who knows... maybe tomorrow I will find a solution.
Friday, January 20, 2006
Myth Busters
Euan started a nice category on his blog... Myth Busters (love that show btw).
Instead of trying to sink a boat with a self constructed shark Euan will try to explain some SQL Server Myths (and probably bust a couple - 1 down... many to go)
Here
Instead of trying to sink a boat with a self constructed shark Euan will try to explain some SQL Server Myths (and probably bust a couple - 1 down... many to go)
Here
Thursday, January 19, 2006
SSIS Performance Tips
Not that I am an experienced SSIS developer but I'll try to give some general guidelines to optimize the performance of bulk import operations.
- Try to get your flat files sorted by the clustered index of the destination table
- Use the 'Fast Parse' option; there are some limitations for date (time) and integer data
- For OLEDB Connections use the Fast Load setting
- Use a SQL Server Destination if possible (can be up to 25% faster!)
- Use BULK_LOGGED recovery model for your SQL Server destinations
- The MaxConcurrentExecutables package setting defines how many tasks can run concurrently (default number of logical cpus + 2)
- Change the EngineThreads property of a task (defaults to 5 but could support more on multi-processor servers - testing is the key)
- Run parallel import steps if possible
- Use the right isolation level for your package and container
- Import into a heap from multiple files in parallel and then recreate the indexes (clustered first then the non-clustered indexes)
Long term memory
Today I convinced a colleague to start blogging by telling him that I consider it my long-term memory.
He is the tool guru aka Mr. Concept (and a bit .NET guru too :p)
http://www.bloglines.com/blog/General1
He is the tool guru aka Mr. Concept (and a bit .NET guru too :p)
http://www.bloglines.com/blog/General1
Monday, January 16, 2006
Treeview AfterSelect and changing focus
When you want to set focus to another control in the AfterSelect method of a treeview there seems to be a problem with the behavior. Focus is set to the control but is then returned to the Treeview.
Forcing the Focus asynchronously seems to solve this little issue.
How?
Add a delegate:
private delegate bool _methodInvoker();
Now in the AfterSelect handler add the following code:
myControl.BeginInvoke(new _methodInvoker(myControl.Focus));
Kept me busy quite some time :-(
Forcing the Focus asynchronously seems to solve this little issue.
How?
Add a delegate:
private delegate bool _methodInvoker();
Now in the AfterSelect handler add the following code:
myControl.BeginInvoke(new _methodInvoker(myControl.Focus));
Kept me busy quite some time :-(
Thursday, January 12, 2006
Missing Indexes Feature
Especially for my favorite colleague Tom :-)
SQL Server hold information about missing indexes in a couple of dmv's.
sys.dm_db_missing_index_group_stats: holds information about the possible performance improvement when implementing a group of indexes
sys.dm_db_missing_index_groups: holds information about possible groups of indexes
sys.dm_db_missing_index_details: holds details about the missing indexes
sys.dm_db_missing_index_columns: holds the list of columns that could use indexes
This is a great feature but as always it has some limitations.
From the BOL:
Remember that it is not the holy grail but yet again a nice addition that guides you in the right direction. Performance remains the responsibility of the DBA that has to make the right decision for the specific workload and configuration available. Proper modeling and indexing remains a key factor in high performance applications that squeeze out the last drop of hardware-power.
SQL Server hold information about missing indexes in a couple of dmv's.
sys.dm_db_missing_index_group_stats: holds information about the possible performance improvement when implementing a group of indexes
sys.dm_db_missing_index_groups: holds information about possible groups of indexes
sys.dm_db_missing_index_details: holds details about the missing indexes
sys.dm_db_missing_index_columns: holds the list of columns that could use indexes
This is a great feature but as always it has some limitations.
From the BOL:
- It is not intended to fine tune an indexing configuration.
- It cannot gather statistics for more than 500 missing index groups.
- It does not specify an order for columns to be used in an index.
- For queries involving only inequality predicates, it returns less accurate cost information.
- It reports only include columns for some queries, so index key columns must
be manually selected.- It returns only raw information about columns on which
indexes might be missing.- It can return different costs for the same missing
index group that appears multiple times in XML Showplans.
Remember that it is not the holy grail but yet again a nice addition that guides you in the right direction. Performance remains the responsibility of the DBA that has to make the right decision for the specific workload and configuration available. Proper modeling and indexing remains a key factor in high performance applications that squeeze out the last drop of hardware-power.
Tuesday, January 10, 2006
Microsoft Minded?
I guess I'm pretty Microsoft minded and with good reason so far.
But some people really go well beyond being 'MS minded' :)
Here
But some people really go well beyond being 'MS minded' :)
Here
Friday, January 06, 2006
Integration Services vs Named Instances
If you are encountering 'Login Timeout' messages when trying to connect to the MSDB database of your Integration Services check if you have installed it on a server with only named instance.
Integration Services points to the default instance of the localhost. If you don't have a default instance you need to change the MsDtsSrvr.ini.xml file in \Program Files\Microsoft SQL Server\90\DTS\Binn. Find the ServerNameconfiguration and change it to point to one of your named instances.
Integration Services points to the default instance of the localhost. If you don't have a default instance you need to change the MsDtsSrvr.ini.xml file in \Program Files\Microsoft SQL Server\90\DTS\Binn. Find the ServerName
Thursday, January 05, 2006
System.Transaction
I'm probably a few months behind but I recently read that the new Windows Vista will support a filesystem and registry that is capable of transactions in combination with the new System.Transaction assembly.
Now that's a very nice feature!
Now that's a very nice feature!
Wednesday, January 04, 2006
An unexpected error occurred in Report Processing. (rsUnexpectedError) - Hotfix
Finally some information about this.
We have confirmation from Microsoft that it is indeed a bug in ALL versions of Reporting Services. A hotfix request will be sent by us to solve this problem.
We have confirmation from Microsoft that it is indeed a bug in ALL versions of Reporting Services. A hotfix request will be sent by us to solve this problem.
Nifty features in Management Studio
As you know Management Studio has lots of improvements and some are quite technical and usefull. Sometimes I stumble upon some little 'improvements' that are more or less cute.
When adding a clustered index to a table with non-clustered indexes I received the following message box.
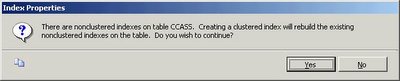
Cute huh :-)
When adding a clustered index to a table with non-clustered indexes I received the following message box.

Cute huh :-)
Tuesday, January 03, 2006
.NET 2.0
Finally found some time this weekend to play around with .NET 2.0.
Although I haven't seen a lot I'm already quite pleased with Master Pages and Themes. There are some nice improvements to the tools too like a tool to manage your web.config, refactoring in Visual Studio, ...
Next on the list:
MARS
Explore the possibilities of the GridView control
Although I haven't seen a lot I'm already quite pleased with Master Pages and Themes. There are some nice improvements to the tools too like a tool to manage your web.config, refactoring in Visual Studio, ...
Next on the list:
MARS
Explore the possibilities of the GridView control
Saturday, December 31, 2005
Deprecation event category - Follow up
As today is a boring day (until tonight of course) I tested the Deprecation event in Profiler.
I know Microsoft has done an amazing effort in getting error descriptions as clear as possible and they succeeded quite nice but this is amazing.
I tried a DBCC SHOWCONTIG which will be replaced and this is what I see in Profiler:
I know Microsoft has done an amazing effort in getting error descriptions as clear as possible and they succeeded quite nice but this is amazing.
I tried a DBCC SHOWCONTIG which will be replaced and this is what I see in Profiler:
DBCC SHOWCONTIG will be removed in a future version of SQL Server. Avoid
using this feature in new development work, and plan to modify applications
that
currently use it. Use sys.dm_db_index_physical_stats instead.
With sp_lock I get the following:
sp_lock will be removed in a future version of SQL Server. Avoid using this
feature in new development work, and plan to modify applications that currently
use it.
The use of more than two-part column names will be removed in a future
version of SQL Server. Avoid using this feature in new development work, and
plan to modify applications that currently use it.
How clear is that?
3..2..1..1
Because of a corrective measure 2005 will be one second longer... enjoy it :-)
Anyway, may I wish you a very happy 2006 where all your dreams come true.
May it also be a year of many SQL Server 2005 implementations in your environment ;-)
Anyway, may I wish you a very happy 2006 where all your dreams come true.
May it also be a year of many SQL Server 2005 implementations in your environment ;-)
Thursday, December 29, 2005
Reporting Services Timeout through SOAP
We have report that is quite large and causes timeouts for one of our offices not surprisingly the one with the most transactions.
So I started looking for the timeout configuration values and I must say Reporting Services has quite a collection of timeout values :-)
We do a nightly generation of PDF files through the means of the RS webservice and it was the call to the webservice that timed out. The behavior wasn't influences by any of the configuration values of Reporting Services. So I started digging deeper and came across the following solution.
Add base.Timeout = 3600 (in milliseconds) to the constructor of the ReportingServiceProxy class.
So I started looking for the timeout configuration values and I must say Reporting Services has quite a collection of timeout values :-)
We do a nightly generation of PDF files through the means of the RS webservice and it was the call to the webservice that timed out. The behavior wasn't influences by any of the configuration values of Reporting Services. So I started digging deeper and came across the following solution.
Add base.Timeout = 3600 (in milliseconds) to the constructor of the ReportingServiceProxy class.
Troubleshooting Performance Problems in SQL Server 2005
Another great whitepaper by Microsoft.
Find it here
Find it here
Wednesday, December 28, 2005
Deprecation event category
Except for the unbelievable blocking process monitoring and the amazing deadlock detection in the new SQL Server 2005 profiler I stumbled upon another nifty feature.
It's the Deprecation event. This event is triggered on statements that will no longer be supported in future versions of SQL Server.
I think it's quite funky that Microsoft includes this in Profiler.
I haven't played around with it yet but as soon as I find some time I'm sure going to.
It's the Deprecation event. This event is triggered on statements that will no longer be supported in future versions of SQL Server.
I think it's quite funky that Microsoft includes this in Profiler.
I haven't played around with it yet but as soon as I find some time I'm sure going to.
Tuesday, December 27, 2005
OPTION FAST vs CONVERT
I was playing around with the OPTION FAST statement for an update query when I saw a 'weird' behavior.
When using the OPTION FAST SQL Server passed the criteria as a fixed value while without it, it would use a variable because of a conversion.
Then I remembered the following article which states a list of situations where auto-parameterization is not happening and one of it is:
Another mystery solved :-)
When using the OPTION FAST SQL Server passed the criteria as a fixed value while without it, it would use a variable because of a conversion.
Then I remembered the following article which states a list of situations where auto-parameterization is not happening and one of it is:
I was passing a uniqueidentifier between single quotes so apparently the auto-parameterization is storing it as a character variable in the cache.A statement with query hints specified using the OPTION clause.
Another mystery solved :-)
Playing around with DBREINDEX/CREATE INDEX
There are many ways to rebuild your indexes in SQL Server 2000 and I felt like doing some performance testing on the different ways.
A DROP and CREATE is obviously the slowest because you are rebuilding your non clustered indexes twice this way. First he has to change the bookmark to the RID because it is becoming a heap instead of a clustered table and then he has to change the bookmark again to point to the clustering key.
CREATE WITH DROP_EXISTING and DBCC DBREINDEX rebuild the clustered index in one transaction preventing the double rebuild of the nonclustered indexes. When you are rebuilding a unique clustered index the nonclustered indexes aren't being rebuilt at all. The same goes for the CREATE WITH DROP_EXISTING if you are recreating the index on the same key.
Keep in mind that creating a clustered index without specifying the UNIQUE keyword gives the opportunity to insert non unique records. When this happens SQL Server adds 4 extra bytes to every key to guarantee the uniqueness. Another side effect is that nonclustered indexes are being rebuilt because the 'uniqueifier' is regenerated every time you rebuild the index and thus changing the clustering key.
One of the 'benefits' of the DROP_EXISTING method vs the DBCC DBREINDEX is the ability to pass the SORT_IN_TEMPDB option. This forces SQL Server to store the intermediate sort results that are used to build the index in tempdb. Although this may increase the index rebuild performance it does take more diskspace.
SQL Server 2005 introduces the ALTER INDEX statement with a REBUILD option.
Here is a little test script (always recreate the table when testing a reindexing method).
There is no time for the ALTER INDEX because I was testing on SQL Server 2000. But it should be about the same as DBCC DBREINDEX as they are supposed the be equivalents.
SET NOCOUNT ON
IF OBJECT_ID('myTest') IS NOT NULL
DROP TABLE myTest
GO
CREATE TABLE myTest
(myID int,
myChar char(512)
)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 1000000
BEGIN
INSERT INTO myTest (myID, myChar)
VALUES (@i, REPLICATE('Z', 512))
SET @i = @i + 1
END
GO
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID)
GO
--Create a ridiculous amount of indexes :)
CREATE NONCLUSTERED INDEX ix1 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix2 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix3 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix4 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix5 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix6 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix7 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix8 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix9 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix10 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix11 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix12 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix13 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix14 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix15 ON myTest (myChar)
GO
--Drop and create - 00:26:39
DECLARE @Start datetime
SET @Start = Getdate()
DROP INDEX myTest.ci1
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID)
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--Create with DROP_EXISTING - 00:01:23
DECLARE @Start datetime
SET @Start = Getdate()
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID) WITH DROP_EXISTING
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--DBREINDEX - 00:01:16
DECLARE @Start datetime
SET @Start = Getdate()
DBCC DBREINDEX(myTest, ci1, 0)
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--ALTER INDEX
DECLARE @Start datetime
SET @Start = Getdate()
ALTER INDEX ci1 ON myTest
REBUILD;
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--Clean up
IF OBJECT_ID('myTest') IS NOT NULL
DROP TABLE myTest
GO
A DROP and CREATE is obviously the slowest because you are rebuilding your non clustered indexes twice this way. First he has to change the bookmark to the RID because it is becoming a heap instead of a clustered table and then he has to change the bookmark again to point to the clustering key.
CREATE WITH DROP_EXISTING and DBCC DBREINDEX rebuild the clustered index in one transaction preventing the double rebuild of the nonclustered indexes. When you are rebuilding a unique clustered index the nonclustered indexes aren't being rebuilt at all. The same goes for the CREATE WITH DROP_EXISTING if you are recreating the index on the same key.
Keep in mind that creating a clustered index without specifying the UNIQUE keyword gives the opportunity to insert non unique records. When this happens SQL Server adds 4 extra bytes to every key to guarantee the uniqueness. Another side effect is that nonclustered indexes are being rebuilt because the 'uniqueifier' is regenerated every time you rebuild the index and thus changing the clustering key.
One of the 'benefits' of the DROP_EXISTING method vs the DBCC DBREINDEX is the ability to pass the SORT_IN_TEMPDB option. This forces SQL Server to store the intermediate sort results that are used to build the index in tempdb. Although this may increase the index rebuild performance it does take more diskspace.
SQL Server 2005 introduces the ALTER INDEX statement with a REBUILD option.
Here is a little test script (always recreate the table when testing a reindexing method).
There is no time for the ALTER INDEX because I was testing on SQL Server 2000. But it should be about the same as DBCC DBREINDEX as they are supposed the be equivalents.
SET NOCOUNT ON
IF OBJECT_ID('myTest') IS NOT NULL
DROP TABLE myTest
GO
CREATE TABLE myTest
(myID int,
myChar char(512)
)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 1000000
BEGIN
INSERT INTO myTest (myID, myChar)
VALUES (@i, REPLICATE('Z', 512))
SET @i = @i + 1
END
GO
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID)
GO
--Create a ridiculous amount of indexes :)
CREATE NONCLUSTERED INDEX ix1 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix2 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix3 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix4 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix5 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix6 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix7 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix8 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix9 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix10 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix11 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix12 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix13 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix14 ON myTest (myChar)
GO
CREATE NONCLUSTERED INDEX ix15 ON myTest (myChar)
GO
--Drop and create - 00:26:39
DECLARE @Start datetime
SET @Start = Getdate()
DROP INDEX myTest.ci1
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID)
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--Create with DROP_EXISTING - 00:01:23
DECLARE @Start datetime
SET @Start = Getdate()
CREATE UNIQUE CLUSTERED INDEX ci1 ON myTest (myID) WITH DROP_EXISTING
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--DBREINDEX - 00:01:16
DECLARE @Start datetime
SET @Start = Getdate()
DBCC DBREINDEX(myTest, ci1, 0)
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--ALTER INDEX
DECLARE @Start datetime
SET @Start = Getdate()
ALTER INDEX ci1 ON myTest
REBUILD;
PRINT CONVERT(varchar,GetDate() - @Start , 108)
--Clean up
IF OBJECT_ID('myTest') IS NOT NULL
DROP TABLE myTest
GO
Thursday, December 22, 2005
DELETE WITH TABLOCKX - Follow up
After some playing around with DBCC PAGE, DBCC EXTENTINFO I came to the conclusion that it is indeed the deallocation that causes the process to take page locks (and extent locks when a complete extent is released).
From Inside SQL Server 2000
So I suppose the spid that does the deletes also deallocates the pages and extents and not the asynchronous process that scans for ghosted records
From Inside SQL Server 2000
When the last row is deleted from a data page, the entire page is deallocated. (If the page is the only one remaining in the table, it isn't deallocated. A table always contains at least one page, even if it's empty.) This also results in the deletion of the row in the index page that pointed to the old data page. Index pages are deallocated if an index row is deleted (which, again, might occur as part of a delete/insert update strategy), leaving only one entry in the index page. That entry is moved to its neighboring page, and then the empty page is deallocated.
So I suppose the spid that does the deletes also deallocates the pages and extents and not the asynchronous process that scans for ghosted records
Wednesday, December 21, 2005
SQL Server 2005 system tables diagram
I read on SQL Server Code about this great system tables diagram.
Download the system tables diagram for SQL Server 2005
Download the system tables diagram for SQL Server 2005
DELETE WITH TABLOCKX
Recently I was playing around with one of our procedures that we use for our reporting solution. One of the requirements was the ability to regenerate data for a certain date. In order to guarantee this we delete the records for a specific day before filling the denormalized tables with data. Because there are a lot of records for 1 day for some reports and we only fill them during the night when there is no activity I thought it would be a good idea to use WITH TABLOCKX because the finer the granularity the more work SQL Server has with managing the locks.
I accidentally came across some strange behavior (imho) when checking the actual locks taken by the process. It seems SQL Server is switching to row and page locks and escalating to table locks at some point even though I hardcoded WITH (TABLOCKX) in the DELETE statement.
Here you can find a little reproduction script:
The funny thing is that the switch to page and row locks is only happening as of a certain number of records (possibly because of the time it takes so some process finishes?)
SET NOCOUNT ON
IF NOT OBJECT_ID('tbltablockTest') IS NULL
DROP TABLE tblTablockTest
GO
CREATE TABLE tblTablockTest
(ID int,
myDate smalldatetime,
myText varchar(1000)
)
GO
DECLARE @i int
SET @i = 1
WHILE @i < 1025
BEGIN
INSERT INTO tblTablockTest
VALUES (@i, getdate(), REPLICATE(CAST(@i as varchar), 1000 / LEN(@i)))
SET @i = @i + 1
END
GO
CREATE CLUSTERED INDEX ixID ON tblTablockTest (ID)
GO
DBCC TRACEON (3604, 1200) --1200 shows detailed information about locking
BEGIN TRAN
DELETE FROM tblTablockTest WITH (TABLOCKX)
WHERE ID BETWEEN 1 AND 15 -- increase the 15 if the behaviour is not showing
ROLLBACK
DBCC TRACEOFF (3604, 1200)
I haven't figured out why this is happening yet but I'm on a mission ;-) One of my guesses is that it has something to do with page deallocation but I haven't got a good explanation yet.
I accidentally came across some strange behavior (imho) when checking the actual locks taken by the process. It seems SQL Server is switching to row and page locks and escalating to table locks at some point even though I hardcoded WITH (TABLOCKX) in the DELETE statement.
Here you can find a little reproduction script:
The funny thing is that the switch to page and row locks is only happening as of a certain number of records (possibly because of the time it takes so some process finishes?)
SET NOCOUNT ON
IF NOT OBJECT_ID('tbltablockTest') IS NULL
DROP TABLE tblTablockTest
GO
CREATE TABLE tblTablockTest
(ID int,
myDate smalldatetime,
myText varchar(1000)
)
GO
DECLARE @i int
SET @i = 1
WHILE @i < 1025
BEGIN
INSERT INTO tblTablockTest
VALUES (@i, getdate(), REPLICATE(CAST(@i as varchar), 1000 / LEN(@i)))
SET @i = @i + 1
END
GO
CREATE CLUSTERED INDEX ixID ON tblTablockTest (ID)
GO
DBCC TRACEON (3604, 1200) --1200 shows detailed information about locking
BEGIN TRAN
DELETE FROM tblTablockTest WITH (TABLOCKX)
WHERE ID BETWEEN 1 AND 15 -- increase the 15 if the behaviour is not showing
ROLLBACK
DBCC TRACEOFF (3604, 1200)
I haven't figured out why this is happening yet but I'm on a mission ;-) One of my guesses is that it has something to do with page deallocation but I haven't got a good explanation yet.
Tuesday, December 20, 2005
SQL Trivia
Got this nice little pop quiz at work (which you are obviously bound to answer wrong).
Given the next SQL Script:
Given the next SQL Script:
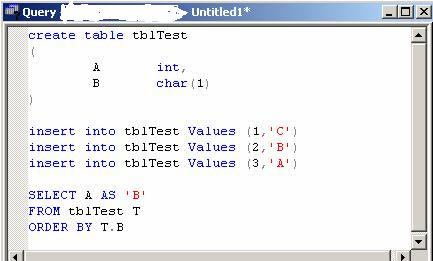
What would the output of the SELECT be?
Now my first reaction was obviously 3, 2, 1 and this would be correct on SQL Server 2005 but unfortunately SQL Server 2000 gives you 1, 2, 3.
Quite frankly I prefer the SQL Server 2005 method anyway ;-)
I lost :-(
Overwrite PDF with Reporting Services through SOAP
I had this really strange issue with one of my reports in development. Obviously developing a report is not something you do in one run. Because of this nice bug in Reporting Services I am only able to check the output by generating the PDF through the Reporting Services webservice.
I was getting this funny behavior of PDF files being correct in size and even page numbers but all the pages were empty. When you eventually scrolled through the PDF it would crash saying that the document is invalid.
Apparently the problem is being caused by overwriting the PDF from the .NET application. Deleting the file before creating it seems to solve this issue.
*EDIT*
Aha, found the nasty bugger :-(
FileStream fs = new FileStream(path, FileMode.OpenOrCreate);
instead of
FileStream fs = new FileStream(path, FileMode.Create);
Developers *sigh* :-D
I was getting this funny behavior of PDF files being correct in size and even page numbers but all the pages were empty. When you eventually scrolled through the PDF it would crash saying that the document is invalid.
Apparently the problem is being caused by overwriting the PDF from the .NET application. Deleting the file before creating it seems to solve this issue.
*EDIT*
Aha, found the nasty bugger :-(
FileStream fs = new FileStream(path, FileMode.OpenOrCreate);
instead of
FileStream fs = new FileStream(path, FileMode.Create);
Developers *sigh* :-D
Monday, December 19, 2005
SQL Server Management Studio - Faster Start
Check out this post for more information about the command line parameters for SSMS.
Adding the nosplash parameter really speeds up starting Management Studio. Just add -nosplash to your SSMS shortcut.
How's that for an easy gain!
Adding the nosplash parameter really speeds up starting Management Studio. Just add -nosplash to your SSMS shortcut.
How's that for an easy gain!
Thursday, December 15, 2005
MSDN Product Feedback Center
As you can see in a post from yesterday there is a nice website that enables you to send suggestions to Microsoft.
Check it out here
Check it out here
Wednesday, December 14, 2005
Those darn statistics
Recently I had this funny query which ignored and index although it seemed very useful to me. Normally I don't question the query optimizer too much but this time I was really sure.
I tried a UPDATE STATISTICS WITH FULLSCAN on the index and all of the sudden my query started to use the index.
Statistics on indexes are always created with fullscan because SQL Server has to scan all of the data anyway. This counts for newly created indexes and reindexing. As far as I can see auto statistics update is always performed by sampling the index or table.
Time for some more testing tomorrow! :-)
I tried a UPDATE STATISTICS WITH FULLSCAN on the index and all of the sudden my query started to use the index.
Statistics on indexes are always created with fullscan because SQL Server has to scan all of the data anyway. This counts for newly created indexes and reindexing. As far as I can see auto statistics update is always performed by sampling the index or table.
Time for some more testing tomorrow! :-)
Product Suggestions
I got around to submit a product suggestion to Microsoft (for SQL Server 2005).
I loved the shortcut to 'Manage Indexes' from the query plan to create some temporary indexes for performance testing. It was a very handy feature that made performance tuning a bit easier. I've submitted a suggestion here (go vote!)
I'm also following 2 other suggestions. One being the complete 'Script As' script with DROP and CREATE statements, check it out here.
Finally there is the very unhandy 'feature' of not being able to load scripts in the current connection and database context, check it out here.
It seems I'm a bit conservative and want isqlw features back :-)
I loved the shortcut to 'Manage Indexes' from the query plan to create some temporary indexes for performance testing. It was a very handy feature that made performance tuning a bit easier. I've submitted a suggestion here (go vote!)
I'm also following 2 other suggestions. One being the complete 'Script As' script with DROP and CREATE statements, check it out here.
Finally there is the very unhandy 'feature' of not being able to load scripts in the current connection and database context, check it out here.
It seems I'm a bit conservative and want isqlw features back :-)
Thursday, December 08, 2005
SQL Server 2005 BOL Update
Wow, Microsoft already released an update of the samples and books online for SQL Server 2005. That's very nice, keep up the good work!
They are already working on the next version btw :)
SQL Server 2005 BOL
SQL Server 2005 Samples
They are already working on the next version btw :)
SQL Server 2005 BOL
SQL Server 2005 Samples
Sunday, December 04, 2005
An unexpected error occurred in Report Processing. (rsUnexpectedError) - Follow up
In this post I had a little problem with Reporting Services.
I didn't have time to investigate it a little deeper until a couple of weeks ago. The problem is that there is no real solution for the time being. Even SQL Server 2005 Reporting Services experiences the same issue.
So I finally decided to submit it to Microsoft Support. They have confirmed that it is a bug in Reporting Services and the developers are looking into it. Let's see how they fix it ;-) I'll keep you posted of course.
I didn't have time to investigate it a little deeper until a couple of weeks ago. The problem is that there is no real solution for the time being. Even SQL Server 2005 Reporting Services experiences the same issue.
So I finally decided to submit it to Microsoft Support. They have confirmed that it is a bug in Reporting Services and the developers are looking into it. Let's see how they fix it ;-) I'll keep you posted of course.
Wednesday, November 30, 2005
New System Objects in SQL Server 2005
One of the first and hardest things to achieve when a new version comes out it get rid of old habits. I'm sure you all used the sysobjects, syscolumns, ... and many others quite often. With SQL Server 2005 however there are some changes and lots of these tables have replacement views and extra information although the old tables are kept for backward compatibility.
Check the BOL for "Mapping SQL Server 2000 System Tables to SQL Server 2005 System Views"
ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/tsqlref9/html/a616fce9-b4c1-49da-87a7-9d6f74911d8f.htm
This contains a nice overview of the old tables and their new replacement view. Also remember the ANSI standard INFORMATION_SCHEMA views which still exist in SQL Server 2005 of course.
Check the BOL for "Mapping SQL Server 2000 System Tables to SQL Server 2005 System Views"
ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/tsqlref9/html/a616fce9-b4c1-49da-87a7-9d6f74911d8f.htm
This contains a nice overview of the old tables and their new replacement view. Also remember the ANSI standard INFORMATION_SCHEMA views which still exist in SQL Server 2005 of course.
Monday, November 28, 2005
Clock Hands
A very interesting post from our favorite SQL Memory Management Guru.
Oh yes... my first day @ work :-)
Oh yes... my first day @ work :-)
Monday, November 21, 2005
Layla
It's been a long time but there is a good reason ;)
My wonderful babygirl Layla was born on 14/11/2005
Weighing 3,110 kg and measuring 48,5cm.
Sleepless nights here they come :-s
My wonderful babygirl Layla was born on 14/11/2005
Weighing 3,110 kg and measuring 48,5cm.
Sleepless nights here they come :-s
Thursday, November 10, 2005
Microsoft SQL Server Management Studio
Like all people I tend to stick to what I know (especially when it comes to tools). I started with SQL Server 6.5 and back in those days isqlw (later Query Analyzer) was really your friend because anything else than creating a table was not really a joyful process. Having this background I am big supporter of Query Analyzer which after all those years I still start using Start - Run - isqlw :-D
When Microsoft announced that the Enterprise Manager and Query Analyzer would be integrated in one big Management Studio I wasn't too happy. Obviously feelings are irrelevant in IT and I felt that I had to face reality one day or another; so I decided to install Management Studio and to start using it from now on.
After some time you will notice that you get used to everything. I have to admit that my unhappy feelings are fading away and I'm beginning to see the 'cool' features of Management Studio. One big improvement is to script all your modifications to an object directly to a Query window instead of the clipboard. Some are simple but very useful like the ability to resize/maximize every window. When it comes to big databases the tree is more intelligent so that it only loads the parts you select. Having to load all tables, stored procedures, ... from all databases while you are perhaps only interested in 1 table in 1 database doesn't make any sense right?
One of the things I immediately changed were the keyboard shortcuts. I'm quite addicted to sp_help and sp_helptext and being able to select an object and get all it's information with a simple shortcut has saved me many hours.
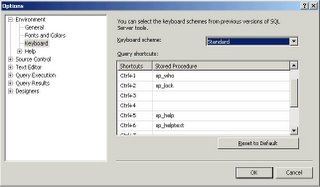
When Microsoft announced that the Enterprise Manager and Query Analyzer would be integrated in one big Management Studio I wasn't too happy. Obviously feelings are irrelevant in IT and I felt that I had to face reality one day or another; so I decided to install Management Studio and to start using it from now on.
After some time you will notice that you get used to everything. I have to admit that my unhappy feelings are fading away and I'm beginning to see the 'cool' features of Management Studio. One big improvement is to script all your modifications to an object directly to a Query window instead of the clipboard. Some are simple but very useful like the ability to resize/maximize every window. When it comes to big databases the tree is more intelligent so that it only loads the parts you select. Having to load all tables, stored procedures, ... from all databases while you are perhaps only interested in 1 table in 1 database doesn't make any sense right?
One of the things I immediately changed were the keyboard shortcuts. I'm quite addicted to sp_help and sp_helptext and being able to select an object and get all it's information with a simple shortcut has saved me many hours.
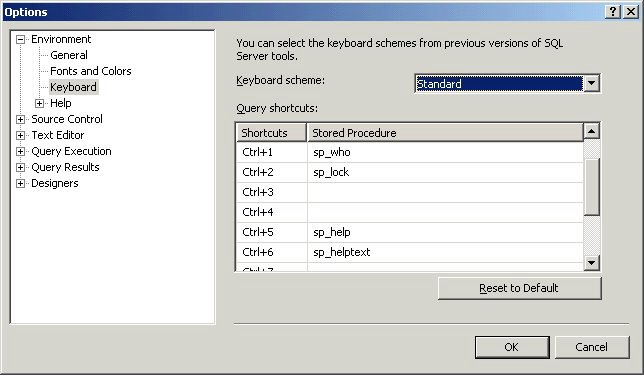
Wednesday, November 09, 2005
Scalable shared databases are supported by SQL Server 2005
A very interesting KB article about Shared Databases
Tuesday, November 08, 2005
Reporting Services 2005 for clientside reports
Aha, I've been given the assignment to investigate the feasibility of Reporting Services 2005 for our online reports in the client application.
This however requires some specific features:
- multiple language
- take xml as input (using xpath in textboxes)
- import of ActiveReports files
- ...
Does anyone have any experience with this yet?
This however requires some specific features:
- multiple language
- take xml as input (using xpath in textboxes)
- import of ActiveReports files
- ...
Does anyone have any experience with this yet?
Thursday, November 03, 2005
SQL Server 2005 Adoption Rates
Check out this report on migrating to SQL Server 2005 by Edgewood Solutions.
Monday, October 31, 2005
Uninstall SQL Server 2005 CTP
With the release of the RTM version you probably all want to remove the CTP version ;-)
There is a handy tool to help you with this process called sqlbuw.exe which can be found in the CTP install directory under Setup Tools\Build Uninstall Wizard\sqlbuw.exe
There is a handy tool to help you with this process called sqlbuw.exe which can be found in the CTP install directory under Setup Tools\Build Uninstall Wizard\sqlbuw.exe
Friday, October 28, 2005
Visual Studio 2005/SQL Server 2005
Oh yes... blog post 1000 about the release probably :-)
But just to make sure... it has arrived!!!
Congratulations to the team and let it come to me now :-D
But just to make sure... it has arrived!!!
Congratulations to the team and let it come to me now :-D
Thursday, October 27, 2005
MCITP: Database Developer
The Microsoft certifications have been reorganized and apparently there is a difference between a database administrator and a database developer.
A very welcome split.
The customer where I'm currently located uses this philosophy too. We have about 7 Development DBA's (including me) and 4 Operational DBA's.
Although most software developers are capable of writing queries it amazes me how little most of them *really* know about SQL Server. On the other hand a database developer's point of view is also very different from that of a database administrator.
I'd like to hear if there are any people out there opposing this split.
Anyway, check out the new certification here
A very welcome split.
The customer where I'm currently located uses this philosophy too. We have about 7 Development DBA's (including me) and 4 Operational DBA's.
Although most software developers are capable of writing queries it amazes me how little most of them *really* know about SQL Server. On the other hand a database developer's point of view is also very different from that of a database administrator.
I'd like to hear if there are any people out there opposing this split.
Anyway, check out the new certification here
Tuesday, October 25, 2005
Monday, October 24, 2005
Wednesday, October 19, 2005
Reporting Services Linked Report Generator
Wow this is one cool tool!
But remember... a fool with a tool is still a fool :-)
But remember... a fool with a tool is still a fool :-)
Tuesday, October 18, 2005
Does it matter if I build the clustered index before/after rebuilding the non-clustered indexes?
I was reading a QA on one of Kimberley's great sessions when I came across this interesting question and even more interesting answer. I had always been told that a rebuild of your clustered index causes a rebuild of your non clustered indices, apparently it needs to be more refined.
Does it matter if I build the clustered index before/after
rebuilding the non-clustered indexes?
You should always create the clustered index before creating non-clustered
index but as for rebuilding - you can rebuild your indexes independently as a
rebuild of the clustered does not (generally) cause a rebuild of the
non-clustered. There is one exception to this rule in SQL Server 2000 – in 2000
ONLY, SQL Server will automatically rebuild the non-clustered indexes when a
non-unique clustered index is rebuild. Why? Because the uniqueifiers are
rebuilt.
Thursday, October 13, 2005
NOLOCK vs Clustered Index Order Part IV
Having a heap doesn't influence the order.
Both queries return the data in the same random order.
I've asked the question to a lot of people already including MVP's, Microsoft Employees... an answer will come :-)
Unfortunately nobody has an immediate answer :-(
I'll keep you posted!
Both queries return the data in the same random order.
I've asked the question to a lot of people already including MVP's, Microsoft Employees... an answer will come :-)
Unfortunately nobody has an immediate answer :-(
I'll keep you posted!
Wednesday, October 12, 2005
Ken Henderson's Guru's Guide to SQL Server Architecture
Please check Ken's post.
Let him know how you feel about including OS information in his new book!
Let him know how you feel about including OS information in his new book!
Monday, October 10, 2005
NOLOCK vs Clustered Index Order Part III
Ok... even worse now :-p
Issuing a DBCC DBREINDEX solves the NOLOCK order problem but then again... not if you have multiple datafiles in your database.
Oh boy :-)
Issuing a DBCC DBREINDEX solves the NOLOCK order problem but then again... not if you have multiple datafiles in your database.
Oh boy :-)
NOLOCK vs Clustered Index Order Part II
Still haven't figured out why exactly it's happening but here's a script for the people that want to try.
CREATE TABLE tblClustered
(ID int,
MyDate smalldatetime,
TestField varchar(50))
GO
CREATE CLUSTERED INDEX ixID ON tblClustered (ID, MyDate)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 1000
BEGIN
INSERT INTO tblClustered (ID, MyDate, TestField) VALUES (RAND() * 1000, CONVERT(varchar, getdate(), 112), REPLICATE('T', 50))
SET @i = @i + 1
END
SELECT * FROM tblClustered (NOLOCK)
SELECT * FROM tblClustered
DROP TABLE tblClustered
CREATE TABLE tblClustered
(ID int,
MyDate smalldatetime,
TestField varchar(50))
GO
CREATE CLUSTERED INDEX ixID ON tblClustered (ID, MyDate)
GO
DECLARE @i int
SET @i = 0
WHILE @i < 1000
BEGIN
INSERT INTO tblClustered (ID, MyDate, TestField) VALUES (RAND() * 1000, CONVERT(varchar, getdate(), 112), REPLICATE('T', 50))
SET @i = @i + 1
END
SELECT * FROM tblClustered (NOLOCK)
SELECT * FROM tblClustered
DROP TABLE tblClustered
NOLOCK vs Clustered Index Order
I'm trying to understand something.
I have a simple table with a Clustered Index on an integer field.
When I use 'SELECT * FROM tblClustered' the records are nicely ordered by the clustered index key. When I use 'SELECT * FROM tblClustered (NOLOCK)' however, the records are returned in a semi-random order. With semi-random I mean that the order is always the same but they are not sorted by the clustered index key. The queryplan is the same, I've tried DBCC DROPCLEANBUFFERS, CHECKPOINT, Restart of the SQL Server Service, you name it...
Obviously you should never rely on the clustered key for the sort order but I'm just trying to figure out what's happening 'inside' that makes this difference.
More to follow!
I have a simple table with a Clustered Index on an integer field.
When I use 'SELECT * FROM tblClustered' the records are nicely ordered by the clustered index key. When I use 'SELECT * FROM tblClustered (NOLOCK)' however, the records are returned in a semi-random order. With semi-random I mean that the order is always the same but they are not sorted by the clustered index key. The queryplan is the same, I've tried DBCC DROPCLEANBUFFERS, CHECKPOINT, Restart of the SQL Server Service, you name it...
Obviously you should never rely on the clustered key for the sort order but I'm just trying to figure out what's happening 'inside' that makes this difference.
More to follow!
Performance Fix for AMD Dual Core users
Something for freaks like me :-)
There seems to be a performance fix for AMD Dual Core users with Windows XP SP2. It's seems like you have to contact Microsoft for the fix and it can't be just downloaded... weird :-s
Source
There seems to be a performance fix for AMD Dual Core users with Windows XP SP2. It's seems like you have to contact Microsoft for the fix and it can't be just downloaded... weird :-s
Source
Business Intelligence
Hmm... now that SQL Server 2005 is getting closer I'd like to acquire some knowledge about Business Intelligence.
Let's start with this article
Let's start with this article
Wednesday, October 05, 2005
SQL Server 2005 Mission Critical High Availability
High availability with SQL Server 2005
Lots of interesting information here
Lots of interesting information here
Tuesday, October 04, 2005
Monday, October 03, 2005
Friday, September 30, 2005
Filter table on NULL value in Reporting Services
I was trying to find the correct filter statement for a NULL value in Reporting Services but I always seemed to fail.
So what's the trick?
Filter: =IsNothing(Fields!YourField.Value)
Operator: =
Value: =True
Notice the = before True as this really makes a difference!
So what's the trick?
Filter: =IsNothing(Fields!YourField.Value)
Operator: =
Value: =True
Notice the = before True as this really makes a difference!
Thursday, September 29, 2005
Wednesday, September 28, 2005
Monday, September 26, 2005
SQL Dependency Viewer
The people from RedGate keep amazing me with great tools.
Check out this tool... bye bye select * from sysdepends :-)
Check out this tool... bye bye select * from sysdepends :-)
Sunday, September 25, 2005
Been a while
It's been a while but there is a very good reason for that :-(
There were some complications with the pregnancy of my girlfriend. The little one wanted to get out already but my girlfriend is only 30 weeks pregnant so it has to stay in a couple of weeks longer.
Anyway, a week and lots of medication later it seems to be under control... for the time being.
So as of tomorrow I should be back on track and posting interesting SQL stuff.
There were some complications with the pregnancy of my girlfriend. The little one wanted to get out already but my girlfriend is only 30 weeks pregnant so it has to stay in a couple of weeks longer.
Anyway, a week and lots of medication later it seems to be under control... for the time being.
So as of tomorrow I should be back on track and posting interesting SQL stuff.
Friday, September 16, 2005
MSDN Webcasts
We all love them but can we find the time to listen to them?
Well Jeffrey Palermo found an interesting way... here
Well Jeffrey Palermo found an interesting way... here
Database Mirroring out???
Hmmm I was reading this article by Paul Flessner when I came across this:
One lesson we learned is that we believe our Database Mirroring feature
needs more time in the hands of customers before we make it generally available
for production use. The feature is complete, has passed extensive internal
testing, and we are committed to making it generally available in the first half
of 2006. We will continue to field-test the feature with customers and will
release it for general use as soon as you tell us it is ready.
Wednesday, September 14, 2005
Saturday, September 10, 2005
Another holiday...
Aaah another week @ home!
Although holiday is a big word... some heavy construction work going on :-p I have to prepare the room for my first little one which is on the way!
Happy happy, joy joy :-D
Although holiday is a big word... some heavy construction work going on :-p I have to prepare the room for my first little one which is on the way!
Happy happy, joy joy :-D
Thursday, September 08, 2005
Wednesday, September 07, 2005
bit or tinyint
I'm looking for some information about the following:
Is it better to use a tinyint field instead of a bit field if you are going to index it? Some people say it would probably be better to use a tinyint because the bit has to be extracted from the bitmask causing some overhead. I haven't found any real deep technical information about this but it sounds acceptable.
So if any of you have real hardcore stuff please post a comment :-D
In case I find some info I'll obviously send a little update!
Is it better to use a tinyint field instead of a bit field if you are going to index it? Some people say it would probably be better to use a tinyint because the bit has to be extracted from the bitmask causing some overhead. I haven't found any real deep technical information about this but it sounds acceptable.
So if any of you have real hardcore stuff please post a comment :-D
In case I find some info I'll obviously send a little update!
Tuesday, September 06, 2005
Insufficient result space to convert uniqueidentifier value to char.
I needed a char representation of a GUID field but couldn't retrieve it because of an obscure error :-s
Insufficient result space to convert uniqueidentifier value to char.
This was caused by a CAST as varchar without specifying the length (or a too short length).
Just using CAST(field as char(36)) solved the problem.
Insufficient result space to convert uniqueidentifier value to char.
This was caused by a CAST as varchar without specifying the length (or a too short length).
Just using CAST(field as char(36)) solved the problem.
Understanding TempDB, table variables v. temp tables and Improving throughput for TempDB
Yet another great post of one of my favorite SQL Server gurus :)
Finding Duplicate Indexes in Large SQL Server Databases
A nice article on how to detect duplicate indexes.
I suppose it happens more than you think...
I suppose it happens more than you think...
Monday, September 05, 2005
Create a PDF from a stored procedure without using 3rd party utils
Hmm, a very funky way to create a PDF in SQL Server :-)
Check it out.
I can't say that I'm a fan of such practices but who knows someone might be able to use it out there.
Check it out.
I can't say that I'm a fan of such practices but who knows someone might be able to use it out there.
Thursday, September 01, 2005
Uninstalling CTP
Want to get rid of previous CTP installations easily?
Check out this post. The VS 2005 Diagnostic and Uninstall Tool does the sometimes difficult task for you!
Check out this post. The VS 2005 Diagnostic and Uninstall Tool does the sometimes difficult task for you!
Tuesday, August 30, 2005
Override isolation level
When setting the transaction isolation level it could be nice to be able to control this on table level regardless of the level specified. SQL Server supports this by adding a WITH in the FROM clause.
Eg.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
SELECT Field FROM table t1
INNER JOIN table2 t2 WITH (READUNCOMMITTED) ON t1.ID = t2.ID
This would cause serializable locks on t1 and read uncommitted on t2.
Eg.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
SELECT Field FROM table t1
INNER JOIN table2 t2 WITH (READUNCOMMITTED) ON t1.ID = t2.ID
This would cause serializable locks on t1 and read uncommitted on t2.
Monday, August 29, 2005
String Summary Statistics
I found this little interesting information in this article
SQL Server 2005 includes patented technology for estimating the selectivity of LIKE conditions. It builds a statistical summary of substring frequency distribution for character columns (a string summary). This includes columns of type text, ntext, char, varchar, and nvarchar. Using the string summary, SQL Server can accurately estimate the selectivity of LIKE conditions where the pattern may have any number of wildcards in any combination. For example, SQL Server can estimate the selectivity of predicates of the following form:
Column LIKE 'string%'
Column LIKE '%string'
Column LIKE '%string%'
Column LIKE 'string'
Column LIKE 'str_ing'
Column LIKE 'str[abc]ing'
Column LIKE '%abc%xy'If there is a user-specified escape character in a LIKE pattern (i.e., the pattern is of the form LIKE pattern ESCAPE escape_character), then SQL Server 2005 guesses selectivity. This is an improvement over SQL Server 2000, which uses a guess for selectivity when any wildcard other than a trailing wildcard % is used in the LIKE pattern, and has limited accuracy in its estimates in that case. The String Index field in the first row set returned by DBCC SHOW_STATISTICS includes the value YES if the statistics object also includes a string summary. The contents of the string summary are not shown. The string summary includes additional information beyond what is shown in the histogram. For strings longer than 80 characters, the first and last 40 characters are extracted from the string and concatenated prior to considering the string in the creation of the string summary. Hence, accurate frequency estimates for substrings that appear only in the ignored portion of a string are not available.
Sunday, August 28, 2005
MySQL
I've been playing with MySQL for a project of a friend of mine (http://www.yawn.be).
I honestly love SQL Server even more now :-) I don't want to talk bad about MySQL itself because I don't know enough about the product to do so. But the tools provided are really sad as opposed to the tools that are included with SQL Server. I just wanted to know the queries that were run and their io, cpu, duration etc (<3 Profiler<3) but apparently there is no way with the standard tools to determine this. Graphical Query plans or even plans like the Text Query Plans in SQL Server... couldn't find it :-(
I honestly love SQL Server even more now :-) I don't want to talk bad about MySQL itself because I don't know enough about the product to do so. But the tools provided are really sad as opposed to the tools that are included with SQL Server. I just wanted to know the queries that were run and their io, cpu, duration etc (<3 Profiler<3) but apparently there is no way with the standard tools to determine this. Graphical Query plans or even plans like the Text Query Plans in SQL Server... couldn't find it :-(
Friday, August 26, 2005
MSDN users to get early access to Visual Studio 2005 tools
According to this article in Infoworld we will have access to a release candidate of SQL Server 2005 and Visual Studio 2005 in September! The final versions would be available mid to end October.
Very good news!
Very good news!
Thursday, August 25, 2005
Using Sp_configure To Change a Value Will Issue DBCC FREEPROCCACHE
Another little known fact I guess but Brian Moran pointed out that issueing an sp_configure triggers the DBCC FREEPROCCACHE which removes all cached procedure plans.
SQL Server Magazine's Reader's Choice Awards
An the award goes to....... A First Look at SQL Server 2005 for Developers.
Congratulations to the authors!
Buy
Congratulations to the authors!
Buy
Wednesday, August 24, 2005
Adding a non nullable column without a default
When trying to add a column with a default that is not nullable to an existing table you get an error message (even when there are no records in the table)
ALTER TABLE dbo.tbl_test
ADD NewColumn smalldatetime NOT NULL
CONSTRAINT DF_ToDrop DEFAULT ('2000-01-01')
ALTER TABLE dbo.tbl_test
DROP CONSTRAINT DF_ToDrop
There is however an easy workaround.ALTER TABLE only allows columns to be added that can contain nulls or have a DEFAULT definition specified. Column 'NewColumn' cannot be added to table 'tbl_test' because it does not allow nulls and does not specify a DEFAULT definition.
ALTER TABLE dbo.tbl_test
ADD NewColumn smalldatetime NOT NULL
CONSTRAINT DF_ToDrop DEFAULT ('2000-01-01')
ALTER TABLE dbo.tbl_test
DROP CONSTRAINT DF_ToDrop
Tuesday, August 23, 2005
sql_variant
sql_variant is one of the datatypes that I don't often see being used although it has it's advantages. It's kind of like a varchar where you would be able to store numeric characters, alphanumeric characters, dates, ... with the difference that on a sql_variant field you would be able to determine of which datatype the value is.
One tip I would give you is to always explicitly cast the value you insert (or update) to the datatype you want it to be. Apparently SQL Server uses 2 extra bytes to determine the extra information like the datatype etc. (eg. int would be 6 bytes).
The SQL_VARIANT_PROPERTY function gives you information about the variant itself like datatype, total bytes, precision ...
For more information visit:
sql_variant
SQL_VARIANT_PROPERTY
One tip I would give you is to always explicitly cast the value you insert (or update) to the datatype you want it to be. Apparently SQL Server uses 2 extra bytes to determine the extra information like the datatype etc. (eg. int would be 6 bytes).
The SQL_VARIANT_PROPERTY function gives you information about the variant itself like datatype, total bytes, precision ...
For more information visit:
sql_variant
SQL_VARIANT_PROPERTY
Monday, August 22, 2005
Back and already having fun
Thursday, August 11, 2005
Holiday
Hi,
I've got 2 weeks off so you might not read very much this week and the week to come :)
Take care
I've got 2 weeks off so you might not read very much this week and the week to come :)
Take care
Thursday, August 04, 2005
Give the New PIVOT and UNPIVOT Commands in SQL Server 2005 a Whirl
Nice article about PIVOT and UNPIVOT in SQL Server 2005
Wednesday, August 03, 2005
This must be painful
Paul Thurrott wrote an article where he urges us to boycott IE because of it's lack of support for standards. Now someone has written a nice reply to this...
Ouch ouch ouch
Ouch ouch ouch
Let’s get into standards now. Guess what, Paul? Your site,
WinSuperSite.com currently has 124
validation errors, according to the W3C’s Markup Validation Service.
Even worse, the page which contains your “Boycott IE” story currently has 207
validation errors. Both pages don’t even define the page’s doctype,
which is almost always the first line of the web page.
Monday, August 01, 2005
Page splits
Page splits are not too good for performance and should be closely watched.
One way of determining whether you are having page splits and how many is to use the function ::fn_dblog (@StartingLSN, @EndingLSN). Passing NULL to the two parameters makes sure that the whole log is being read.
eg.
SELECT [Object Name], [Index Name], COUNT(*)
FROM ::fn_dblog(NULL, NULL)
WHERE Operation = 'LOP_DELETE_SPLIT'
GROUP BY [Object Name], [Index Name]
ORDER BY COUNT(*) DESC
You can reduce page splits by specifying a good fill factor. There is no real rule of thumb about fill factors. It all depends on the rowsize and number of rows inserted (between index rebuilds). So specifying a good fill factor and a DBCC DBREINDEX from time to time will minimize the number of page splits.
One way of determining whether you are having page splits and how many is to use the function ::fn_dblog (@StartingLSN, @EndingLSN). Passing NULL to the two parameters makes sure that the whole log is being read.
eg.
SELECT [Object Name], [Index Name], COUNT(*)
FROM ::fn_dblog(NULL, NULL)
WHERE Operation = 'LOP_DELETE_SPLIT'
GROUP BY [Object Name], [Index Name]
ORDER BY COUNT(*) DESC
You can reduce page splits by specifying a good fill factor. There is no real rule of thumb about fill factors. It all depends on the rowsize and number of rows inserted (between index rebuilds). So specifying a good fill factor and a DBCC DBREINDEX from time to time will minimize the number of page splits.
Subscribe to:
Posts (Atom)
